Rozdział 8 Korelacja
Asocjacja (lub „korelacja” w szerokim znaczeniu) to pojęcie statystyczne, które opisuje sytuację, w której dwie zmienne zmieniają się razem. Dwie zmienne są powiązane (skorelowane), gdy znajomość wartości jednej z nich dostarcza informacji o drugiej. Miary korelacji wskazują, czy ta zależność występuje i jak silnie zmienne są ze sobą powiązane.
8.1 Wykres rozrzutu
Wykres rozrzutu jest jednym z najprostszych i najważniejszych narzędzi do badania zależności między dwiema zmiennymi ilościowymi. Przedstawia on dane w formie punktów na dwuwymiarowej płaszczyźnie, gdzie: oś pozioma (oś x) reprezentuje jedną ze zmiennych, podczas gdy oś pionowa (oś y) reprezentuje drugą zmienną.
Każdy punkt na wykresie odpowiada pojedynczej obserwacji.
Wykresy rozrzutu pozwalają nam wizualnie ocenić:
Kierunek związku: trend wzrostowy wskazuje na dodatnią korelację (wraz ze wzrostem X, Y ma tendencję do wzrostu), podczas gdy trend spadkowy wskazuje na ujemną korelację (wraz ze wzrostem X, Y ma tendencję do spadku).
Formę relacji: liniowa vs nieliniowa
Siłę powiązania: punkty ściśle skupione wzdłuż linii (prostej) wskazują na silną (liniową) korelację.
Potencjalne wartości odstające i obserwacje wpływowe: są to punkty, które znacznie odbiegają od ogólnego wzorca.
Rysunek 8.1: Wykres rozrzutu przedstawiający relację między wzrostem 1078 ojców i wzrostem ich dorosłych synów. Anglia, około 1900 roku. Ten zestaw danych został wykorzystany przez Pearsona do zilustrowania korelacji. Na potrzeby tego wykresu oryginalne pomiary (w calach) zostały przeliczone na centymetry przy użyciu wzoru: cale × 2,54.
Niekiedy pomocna może się okazać skala logarytmiczna na jednej lub obu osiach. Taka skala:
„rozrzedza” wartości, gdy liczby obejmują bardzo szeroki zakres, dzięki czemu nie są one „zgniatane” razem;
wyraźniej ujawnia wzorce, np. gdy dane rosną lub zmieniają się procentowo;
zmniejsza „odstawanie” dużych wartości odstających, dzięki czemu nie dominują one na wykresie.
Należy jednak pamiętać, że:
na skali logarytmicznej nie umieścimy zera ani liczb ujemnych;
takie skale mogą być dla niektórych osób trudniejsze do odczytu i interpretacji niż skale liniowe.
Rysunek 8.2: Interaktywny wykres rozrzutu dla 62 gatunków ssaków. Przełączniki umożliwiają skalowanie logarytmiczne dla obu osi w celu lepszej wizualizacji zależności w szerokim zakresie rozmiarów ciała i mózgu.
8.2 Współczynnik korelacji Pearsona
Współczynnik korelacji Pearsona mierzy siłę związku (korelacji, asocjacji, statystycznego skojarzenia, współzależności) między dwiema zmiennymi ilościowymi. Współczynnik korelacji może przyjmować wartości w zakresie od -1 do 1 (włącznie).
Należy pamiętać, że jeśli ktoś używa terminu korelacja bez dalszych wyjaśnień, zwykle odnosi się to do współczynnika korelacji Pearsona.
Korelacja równa dokładnie 1 lub -1 wskazuje na funkcyjną, liniową zależność między dwiema zmiennymi. W tym przypadku znak (1 lub -1) zależy od znaku nachylenia funkcji pozwalającej przekształcać jedną zmienną w drugą.
Im „luźniej” punkty są zgromadzone wokół linii prostej, tym bliższa zeru jest wartość współczynnika korelacji Pearsona. Punkty zgromadzone ciasno wokół linii prostej odpowiadają wartościom współczynnika bliskim 1 lub -1. Współczynnik może być również bliski zeru, gdy linia prosta, wokół której skupione są punkty jest pozioma (równoległa do osi x).
Jeżeli „chmura punktów” na wykresie rozrzutu wnosi się w kierunku wzrostu wartości na osi x (czyli w prawo), oznacza to, że w miarę wzrostu jednej zmiennej, rośnie — średnio rzecz biorąc — również druga. W takiej sytuacji korelacja jest dodatnia.
Ujemna korelacja występuje, kiedy chmura punktów na wykresie rozrzutu opada (w prawo). Dzieje się tak wtedy, gdy w miarę wzrostu jednej zmiennej tzn. gdy jedna zmienna rośnie, druga maleje.
Rysunek 8.3 przedstawia przykładowe wykresy rozrzutu oparte na symulowanych danych dla różnych poziomów nieujemnych (\(\geqslant 0\)) współczynników korelacji.
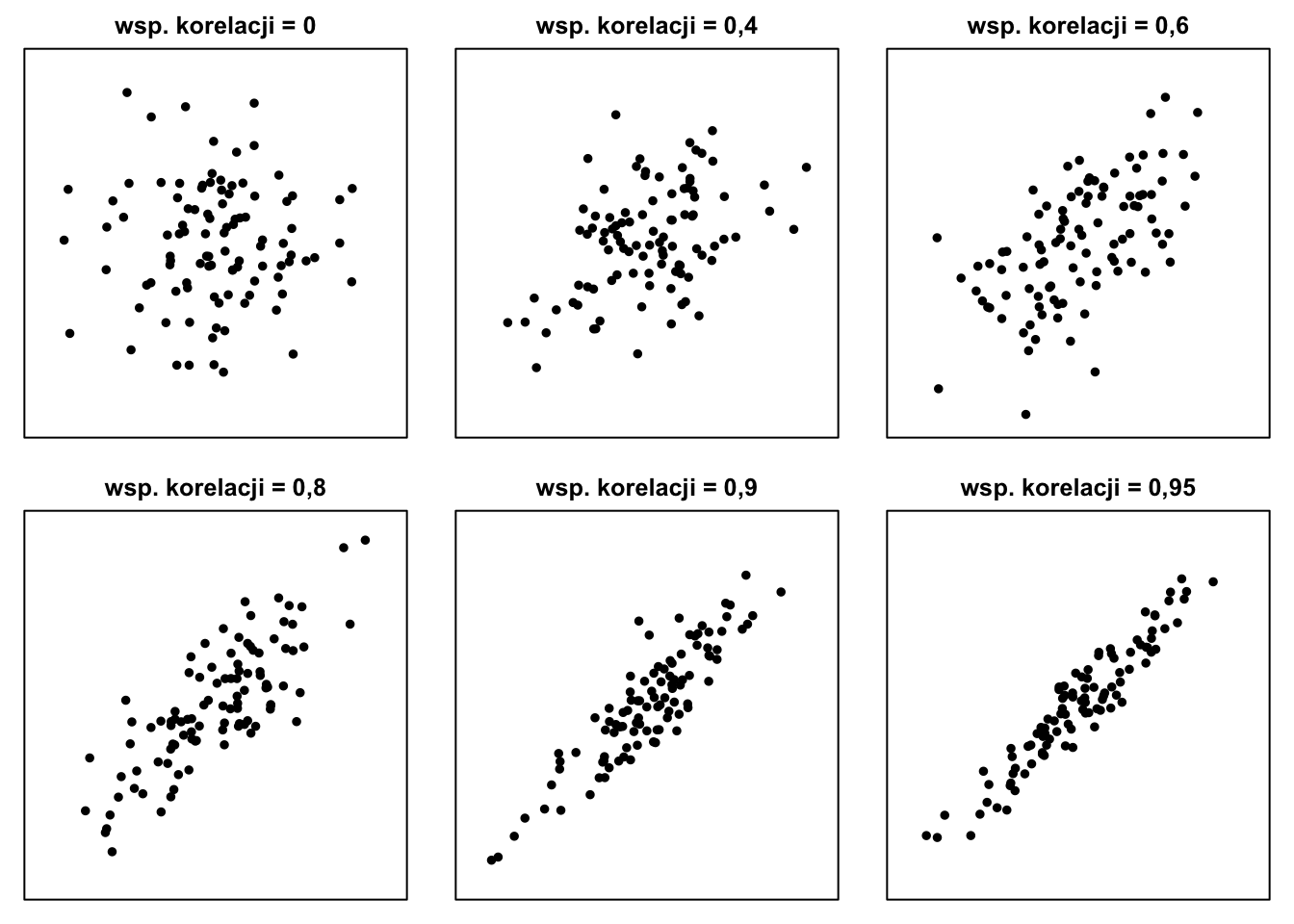
Rysunek 8.3: Przykładowe wykresy rozrzutu dla nieujemnych wartości współczynnika korelacji
W przypadku ujemnej korelacji (jak pokazano na rysunku 8.4 „chmury punktów” opadają w dół:
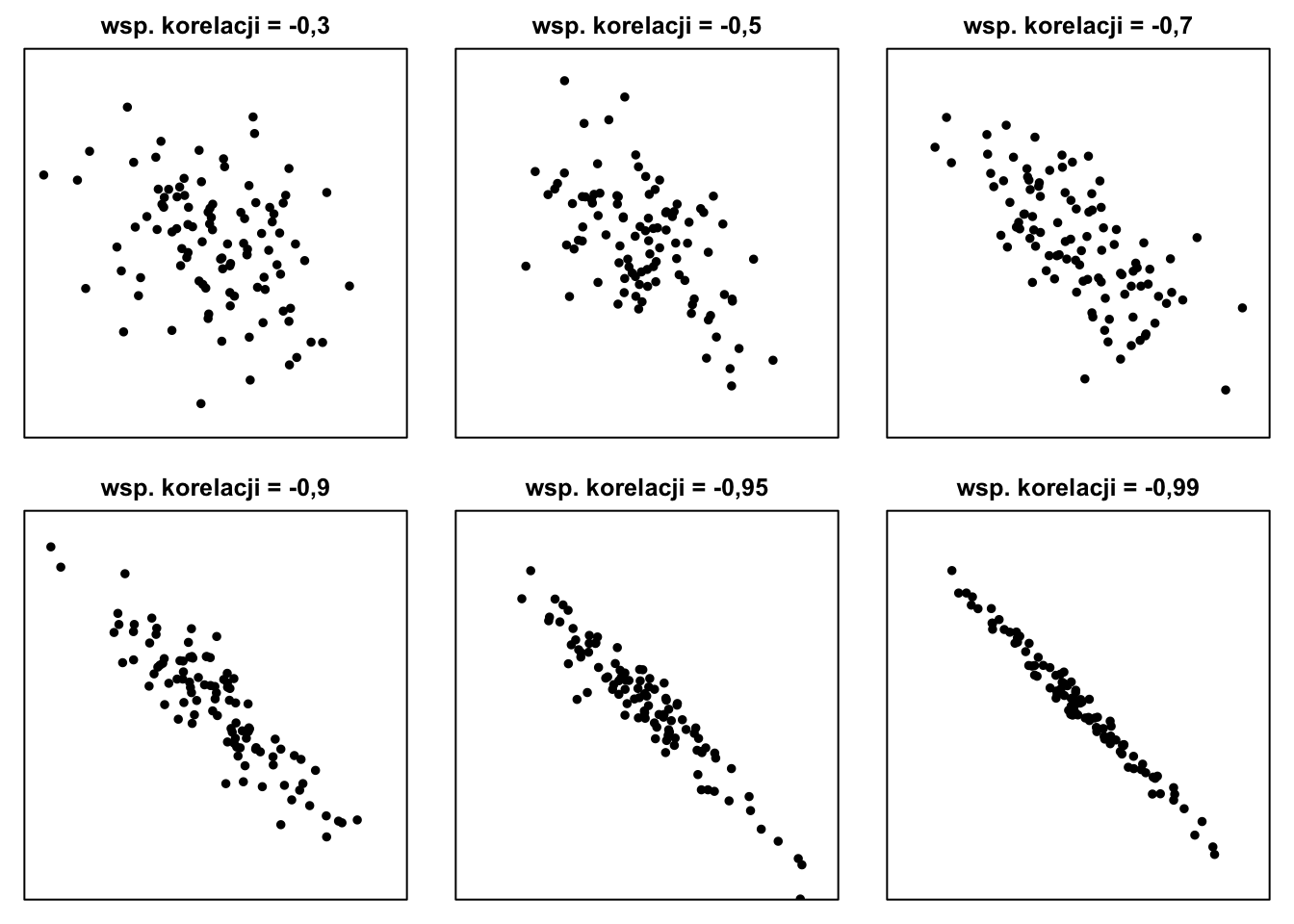
Rysunek 8.4: Przykładowe wykresy rozrzutu dla ujemnych wartości współczynnika korelacji
Jeżeli na wykresie rozrzutu punkty układają się tak, jak przedstawiono na wykresach 8.3 i 8.4 — tzn. grupują się wokół linii prostej, a w przypadku niższej współzależności kształt przypomina pochyloną elipsę, — wówczas wspólny rozkład dwóch zmiennych można opisać za pomocą pięciu liczb:
średniej zmiennej X,
odchylenia standardowego zmiennej X,
średniej zmiennej Y,
odchylenia standardowego zmiennej Y
oraz współczynnika korelacji pomiędzy zmienną X i zmiennej Y.
8.2.1 Współczynnik korelacji - wzór
Wzór na współczynnik korelacji można zapisać na kilka równoważnych sposobów.
Używając tylko wartości zmiennych X i Y oraz ich średnich, współczynnik korelacji Pearsona (oznaczany tutaj jako \(r(X,Y)\) lub \(r_{xy}\))5 może być obliczony jako:
\[r(X,Y) = \frac{\sum_i{(x_i-\bar{x})(y_i-\bar{y})}}{\sqrt{\sum_i(x_i-\bar{x})^2\sum_i(y_i-\bar{y})^2}} \tag{8.1} \]
Łatwiejszy do zapamiętania jest następujący wzór: współczynnik korelacji to średni iloczyn zestandaryzowanych (z-scores, patrz (5.1)) wartości zmiennej X i Y6:
\[r(X,Y) = \frac{1}{n}\sum_{i=1}^n z_{x_i} z_{y_i} = \frac{1}{n}\sum_{i=1}^n\left(\frac{x_i-\bar{x}}{\widehat{\sigma}_X}\right) \left(\frac{y_i-\bar{y}}{\widehat{\sigma}_Y}\right) \tag{8.2} \]
Korelacja dla próbki jest często oznaczana przez \(r\), podczas gdy korelacja dla populacji może być oznaczana przez \(\rho\) („rho”). Jeśli nie wynika to jasno z kontekstu, warto określić, do których zmiennych odnosi się korelacja (np. pisząc \(r(X,Y)\), \(r_{xy}\), \(\rho_{XY}\) itp.)
8.2.2 Współczynnik korelacji Pearsona - właściwości
Współczynnik korelacji Pearsona jest bezwymiarowy, nie zależy od jednostek miary, przyjmuje wartośc zawsze między -1 a 1.
Współczynnik korelacji Pearsona jest symetryczny:
\[r(X, Y) = r(Y, X)\].
Współczynnik korelacji Pearsona jest wrażliwy na wartości odstające: pojedyncza wartość ekstremalna może znacząco zmienić korelację.
Współczynnik korelacji Pearsona jest niezmienniczy przy przekształceniach liniowych: gdy przekształcimy X i/lub Y dodając stałą lub mnożąc przez dodatnią stałą, wartość korelacji nie zmieni się.
Korelacja Pearsona mierzy przede wszystkim siłę i kierunek liniowej zależności między dwiema zmiennymi. Chociaż może ona uchwycić niektóre aspekty nieliniowych relacji, nie jest przeznaczona do ich dokładnego ujęcia.
8.2.3 Jakie wartości współczynnika oznaczają silną korelację?
Odpowiedź na tak zadane pytanie zależy od dziedziny. Współczynnik korelacji na poziomie 0,50 może być uznany za silny w ekonomii, umiarkowany w biologii i słaby w fizyce, gdzie pomiary są często bardziej precyzyjne. Aby ocenić siłę korelacji, należy się odwołać się do przykładów z tej samej dziedziny oraz doświadczenia
Czasami podręcznikowe wzorce stanowią użyteczny punkt wyjścia. Evans (1996) podaje, że wartość bezwzględną współczynnika korelacji można interpretować w następujący sposób:
0,00-0,19 - korelacja „bardzo słaba lub nieznaczna”
0,20-0,39 - „słaba”
0,40-0,59 - „umiarkowana”
0,60-0,79 - „silna”
0,80-1,0 - „bardzo silna”
Oczywiście współczynnik korelacji równy 1 lub -1 oznacza idealną zależność liniową.
W przypadku nauk społecznych (w tym ekonomii) Cohen (2016) zaproponował następujące ogólne wytyczne:
0,10 - „mała”
0,30 - „średnia”
0,50 - „duża”.
8.2.4 Kowariancja
Kowariancja to kolejna miara, która wskazuje, jak dwie zmienne zmieniają się razem.
Wzór na kowariancję, często nazywany „wzorem dla próby”, jest następujący:
\[s_{xy} = \frac{\sum_{i=1}^n \left(x_i-\bar{x}\right)\left(y_i-\bar{y}\right)}{n-1} \tag{8.3}\]
Wzór „sigma” (czasami określany jako „kowariancja populacji”, choć sporadycznie używany dla próbek) to:
\[ \widehat{\sigma}_{xy} = \frac{\sum_{i=1}^n \left(x_i-\bar{x}\right)\left(y_i-\bar{y}\right)}{n} \tag{8.4} \]
Współczynnik korelacji liniowej Pearsona może być interpretowany (i obliczany) jako standaryzowana kowariancja:
\[r_{xy} = \frac{s_{xy}}{s_x s_y} \tag{8.5} \]
lub przy użyciu wersji \(\sigma\):
\[r_{xy} = \frac{\widehat{\sigma}_{xy}}{\widehat{\sigma}_x \widehat{\sigma}_y} \tag{8.6} \]
W tych wzorach \(s_{xy}\) to kowariancja „próbki” (8.3), \(\widehat{\sigma}_{xy}\) to kowariancja „sigma” (8.4); \(s_x\), \(s_y\), \(\widehat{\sigma}_x\), \(\widehat{\sigma}_y\) są odchyleniami standardowymi (patrz (4.2) i (4.1)) zmiennych \(X\) i \(Y\).
8.3 Korelacja i przyczynowość
Gdy X i Y są skorelowane, możliwe jest, że
- X może bezpośrednio powodować Y,
- lub poprzez zmienną pośredniczącą;
- Y może powodować X (bezpośrednio lub pośrednio),
- może istnieć trzecia zmienna, zmienna zakłócająca;
- struktura może być bardziej złożona
- korelacja może być całkowicie fałszywa, spowodowana przypadkiem lub trendami.
Correlation does not imply causation, czyli korelacja nie implikuje związku przyczynowo-skutkowego to fundamentalna zasada w statystyce. Tylko dlatego, że dwie zmienne poruszają się razem, nie oznacza, że jedna powoduje drugą. Na przykład sprzedaż lodów i liczba utonięć wzrastają latem, ale kupowanie lodów nie powoduje utonięć – czynnikiem leżącym u podstaw jest pora roku. Mylenie korelacji z przyczynowością może prowadzić do mylących wniosków, dlatego przed stwierdzeniem związku przyczynowo-skutkowego konieczne są dokładne analizy, kontrolowane eksperymenty lub dodatkowe przesłanki.
8.4 Współczynnik korelacji rang Spearmana
Współczynnik korelacji Spearmana to po prostu współczynnik korelacji Pearsona zastosowany do rang (ang. ranks) zmiennych X i Y.
\[r_S (X, Y) =r\left(\text{Rank}(X), \text{Rank}(Y)\right) \tag{8.7} \]
Oznacza to, że aby obliczyć korelację rang Spearmana, najpierw zastępujemy każdą wartość \(x_i\) i \(y_i\) jej rangą, a następnie obliczamy korelację Pearsona na tych rangach.
8.4.1 Zamiana wartości cechy na rangi
W praktyce statystycznej rangi są zwykle przypisywane w porządku rosnącym: najmniejsza wartość otrzymuje rangę 1, następna rangę 2 i tak dalej.
Kiedy wartości cechy powtarzają się, stosuje się średnią z rang, które przysługiwałyby powtórzonym wartościom. Mówimy wtedy o wartościach/rangach „wiązanych".
Przykład:
| x | rank(x) | y | rank(y) | |
|---|---|---|---|---|
| 6 | 3 | 5 | 1,5 | |
| 8 | 4 | 5 | 1,5 | |
| 5 | 2 | 9 | 3,0 | |
| -1 | 1 | 11 | 4,0 | |
| 10 | 5 | 14 | 6,0 | |
| 39 | 6 | 14 | 6,0 | |
| 100 | 7 | 14 | 6,0 | |
| 101 | 8 | 20 | 8,0 |
Jeśli nie ma rang wiązanych (każda wartość \(x_i\) jest inna oraz każda wartość \(y_i\) jest inna), korelację Spearmana można również obliczyć za pomocą alternatywnego wzoru:
\[ r_s = 1 - \frac{6\sum_{i=1}^n d_i^2}{n(n^2-1)} \tag{8.8} \]
gdzie \(n\) to, jak zwykle, wielkość próby (liczba obserwacji w zbiorze danych), a \(d_i\) to różnica między rangami dla \(i\)-tej obserwacji:
\[d_i = \text{Rank}(x_i) - \text{Rank}(y_i) \]
Równanie (8.8) daje taki sam wynik jak równanie (8.7) tylko wtedy, gdy nie ma wiązanych rang. Jeśli występują, należy użyć równania (8.8).
8.4.2 Właściwości współczynnika korelacji Spearmana
Współczynnik Spearmana wykrywa, czy zmienne poruszają się razem monotonicznie (konsekwentnie w górę lub konsekwentnie w dół). Mierzy siłę i kierunek związku monotonicznego.
Właściwości:
Jest odpowiedni dla danych porządkowych lub nieliniowych zależności monotonicznych .
Jego zakres wartości wynosi od -1 do 1:
+1: idealna rosnąca zależność monotoniczna,
-1: idealna malejąca zależność monotoniczna,
0: brak powiązania monotonicznego.
Jest znacznie bardziej odporny („wytrzymały”) na wartości odstające (wartości ekstremalne mają ograniczony wpływ), nierówne odstępy między danymi i niestałą wariancję niż współczynnik Pearsona.
Monotoniczne transformacje nie zmieniają jego wartości.
8.5 Tau Kendalla
Tau Kendalla (znane również jako współczynnik korelacji rang Kendalla) to kolejna miara asocjacji, która może być używana dla zmiennych ilościowych i porządkowych.
Zamiast polegać na różnicach rang (jak w przypadku współczynnika Spearmana), tau Kendalla opiera się na zgodności porządku. Przy wyznaczaniu współczynnika rozpatruje się wszystkie możliwe pary obserwacji i sprawdza, czy rangi zmiennych (X) i (Y) zmieniają się w tym samym kierunku (pary zgodne) czy w kierunkach przeciwnych (pary niezgodne). Współczynnik ten jest obliczany jako znormalizowana różnica między liczbą par zgodnych i niezgodnych:
\[\tau_A = \frac{\text{liczba par zgodnych} - \text{liczba par niezgodnych}}{ \text{liczba par} } \tag{8.9} \]
„Liczba par” (\(N_0\)), obejmuje pary zgodne, pary niezgodne, a także pary wiązane, w których wartość co najmniej jednej zmiennej (\(X\) i \(Y\)) jest taka sama dla dwóch obserwacji. Dla zbioru danych o rozmiarze \(n\) całkowita liczba unikalnych par wynosi:
\[N_0 = \text{liczba par zgodnych} + \text{liczba par niezgodnych} + \text{liczba remisów} = \\ = \frac{n(n-1)}{2} \tag{8.10}\]
Współczynnik tau Kendalla waha się od -1 do 1 i, podobnie jak współczynnik Spermana, mierzy siłę i kierunek monotonicznego powiązania i dobrze nadaje się do danych porządkowych lub nieliniowych relacji monotonicznych.
W R (i w wielu pakietach statystycznych) używana jest poprawiona wersja tau Kendalla, znana jako \(\tau_B\) Kendalla. Ten wariant dostosowuje się do wiązań występujących w obu zmiennych:
\[\tau_B = \frac{\text{liczba par zgodnych} - \text{liczba par niezgodnych}}{ \sqrt{(N_0-N_1)(N_0-N_2)}} \tag{8.11} \]
gdzie \(N_0 = n(n-1)/2\) jest całkowitą liczbą par,
\(N_1\) to liczba par wiązanych na \(X\),
\(N_2\) to liczba par wiązanych na \(Y\).
Współczynnik Kendalla \(\tau_B\) został wprowadzony, aby uwzględnić korektę wynikającą z wystepowania wiązań w obu zmiennych, zapewniając odpowiednio skalowaną miarę powiązania rangi, gdy występują powtarzające się wartości.
8.6 Test korelacji
Test korelacji to procedura statystyczna stosowana do oceny, czy istnieje liniowy związek między dwiema zmiennymi ilościowymi w populacji (lub, bardziej ogólnie, w procesie generującym dane), wykorzystująca dane z próby.
Najczęściej stosowaną wersją jest test korelacji Pearsona, który ocenia hipotezę zerową, że prawdziwy współczynnik korelacji Pearsona w procesie generującym dane jest równy zero.
Oprogramowanie statystyczne zazwyczaj podaje wartość p (ang. p-value), zdefiniowaną tutaj jako prawdopodobieństwo – obliczone przy założeniu, że hipoteza zerowa jest prawdziwa (tj. przy założeniu, że korelacja w procesie generującym dane wynosi zero) – uzyskania korelacji próbkowej co najmniej tak skrajnej, jak obserwowana (co do wartości bezwzględnej) wyłącznie z powodu losowej zmienności związanej z próbkowaniem.
Przykład
##
## Pearson's product-moment correlation
##
## data: height and head_circ
## t = 2.1406, df = 47, p-value = 0.03753
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.01839182 0.53445132
## sample estimates:
## cor
## 0.298047Zebraliśmy dane od 49 studentów płci męskiej na temat ich wzrostu i obwodu głowy. Myślimy o tych liczbach jako o wyniku procesu, który generuje dane: studenci różnią się naturalnie pod względem wymiarów ciała, pomiary nie są idealnie precyzyjne, a konkretna grupa uczniów, którą obserwowaliśmy, mogła się różnić od populacji z powodów czysto losowych.
W tym zbiorze danych korelacja Pearsona między wzrostem a obwodem głowy wynosi \(r=0{,}298\). Aby zrozumieć, czy wartość ta może wynikać po prostu z przypadkowego ułożenia się danych, a nie z zależności pomiędzy wzrostem a wielkością głowy, zadajemy następujące pytanie: Jeśli wzrost i obwód głowy nie byłyby systematycznie powiązane, jak często widzielibyśmy w podobnych danych – wyłącznie ze względów losowych – korelację co najmniej tak dużą, jak zaobserwowana?
Odpowiedzią na to pytanie jest tzw. wartość p (ang. p-value). W tym przypadku wartość p wynosi 0,038, co oznacza, że korelacje tej wielkości lub większe pojawiłyby się w około 4 na 100 zestawów niezależnych danych o takiej liczebności po prostu z powodu losowej zmienności. Ponieważ zdarza się to stosunkowo rzadko (czyli inaczej: ponieważ mało prawdopodobne jest zaobserwowanie takiej korelacji z powodów czysto losowych), stwierdzamy, że proces generujący dane charakteryzuje się pewnym dodatnim związkiem między wzrostem a obwodem głowy.
8.7 Linki
Gra w zgadywanie korelacji:
https://istats.shinyapps.io/guesscorr/
Inna gra w zgadywanie korelacji:
https://www.guessthecorrelation.com
Gra(y) w odwrotną korelację:
https://college.cengage.com/nextbook/statistics/utts_13540/student/html/simulation3_3_1.html;
https://college.cengage.com/nextbook/statistics/utts_13540/student/html/simulation3_3_2.html;
https://college.cengage.com/nextbook/statistics/utts_13540/student/html/simulation3_3_3.html;
Fałszywe korelacje:
https://www.tylervigen.com/spurious-correlations
Wykresy rozrzutu i korelacje – aplikacja internetowa:
https://rpsychologist.com/correlation/
Przykłady korelacji – aplikacja internetowa:
https://istats.shinyapps.io/Association_Quantitative/
Dodatkowe przykłady korelacji:
korelacja między niedawnym wzrostem dochodów osobistych a wynikami wyborów w USA: https://avehtari.github.io/ROS-Examples/ElectionsEconomy/hibbs.html
korelacja między gęstością zaludnienia a stosunkiem płci (stosunek mężczyzn do kobiet) w polskich regionach: https://blazejkochanski.pl/post/farmer/
korelacje między wzrostem, masą ciała, wiekiem i dochodem w przypadku małżeństw: https://blazejkochanski.pl/post/marital-correlations/
korelacje regionalne w Stanach Zjednoczonych: https://college.cengage.com/nextbook/statistics/utts_13540/student/html/simulation3_2.html
rozmiar ciała a rozmiar mózgu u ssaków: https://www.reddit.com/r/dataisbeautiful/comments/poq0ks/oc_brain_size_vs_body_weight_of_various_animals/#lightbox
8.8 Pytania
8.8.1 Pytania do dyskusji
Pytanie 8.1 (Freedman, Pisani, and Purves 2007) Ile wynosi współczynnik korelacji Pearsona dla danych przedstawionych na tym wykresie rozrzutu? Czy istnieje korelacja (związek) między x i y?
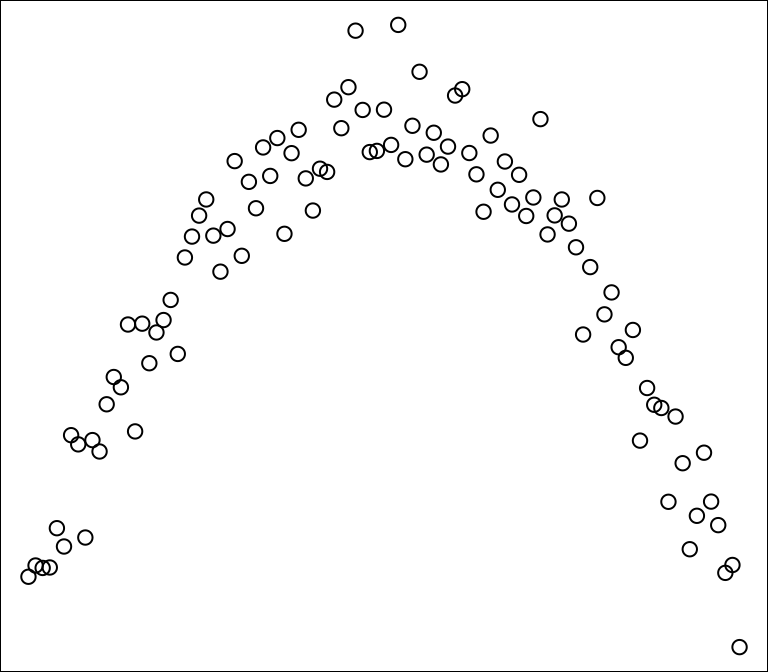
Pytanie 8.2 (Freedman, Pisani, and Purves 2007) Dla pewnego zestawu danych współczynnik korelacji = 0,57. Wskaż, czy każde z poniższych stwierdzeń jest prawdziwe, czy fałszywe; krótko wyjaśnij. Jeśli potrzebujesz więcej informacji, powiedz, czego potrzebujesz i dlaczego.
Nie ma wartości odstających.
Istnieje związek między analizowanymi cechami.
Pytanie 8.3 (Freedman, Pisani, and Purves 2007) W przypadku dzieci w wieku szkolnym rozmiar buta jest silnie skorelowany z umiejętnością czytania. Jak to możliwe?
Pytanie 8.4 (Freedman, Pisani, and Purves 2007) Korelacja między wzrostem a masą ciała wśród mężczyzn w wieku 18-74 lat w USA wynosi około 0,40. Powiedz, czy każdy z poniższych wniosków wynika z danych; wyjaśnij swoją odpowiedź.
Wyżsi mężczyźni są zazwyczaj ciężsi.
Korelacja między masą ciała a wzrostem dla mężczyzn w wieku 18-74 lat wynosi około 0,40.
Ciężsi mężczyźni są zazwyczaj wyżsi.
Jeśli ktoś je więcej i przybiera na wadze 10 kilogramów, prawdopodobnie będzie nieco wyższy.
Pytanie 8.5 (Freedman, Pisani, and Purves 2007) Badania wykazały ujemną korelację między godzinami spędzonymi na oglądaniu telewizji a wynikami testów czytania. Czy oglądanie telewizji sprawia, że ludzie gorzej czytają?
Pytanie 8.6 (Freedman, Pisani, and Purves 2007) Wiele badań wykazało związek (i związek przyczynowy!) między paleniem papierosów a chorobami serca. Jedno z badań wykazało związek między piciem kawy a chorobami serca. Czy należy wnioskować, że picie kawy powoduje choroby serca? A może jest jakieś inne wytłumaczenie?
8.8.2 Pytania testowe
Pytanie 8.7 Okrąg o średnicy d ma pole powierzchni \(\frac{1}{4}\pi d^2\). Wykreślamy wykres rozrzutu pola powierzchni względem średnicy dla próbki okręgów.
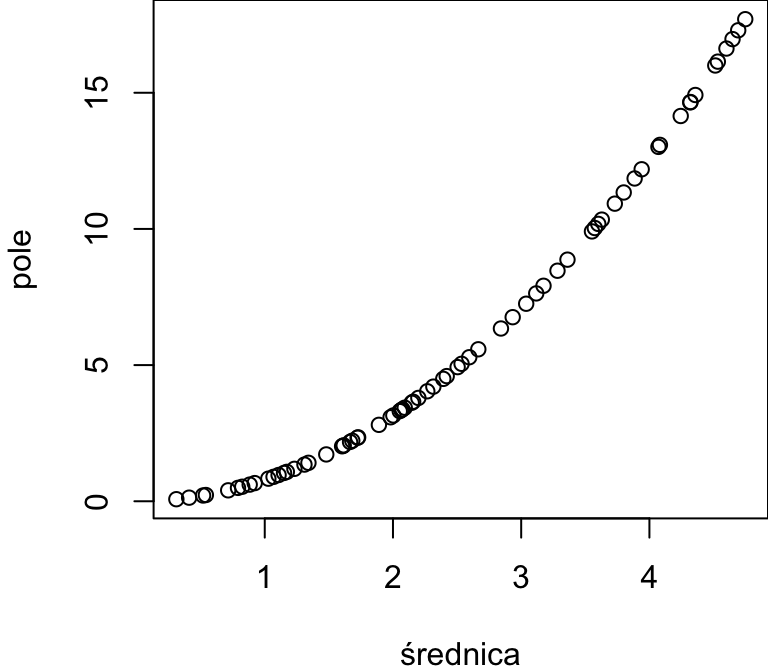
Współczynnik korelacji Pearsona wynosi
Współczynnik korelacji Spearmana wynosi
Pytanie 8.8 Badacz mierzy wzrost dzieci w centymetrach, a następnie przelicza na cale za pomocą wzoru:
\[ \text{cale} = \frac{\text{centymetry}}{2{,}54}\]
Co można będzie powiedzieć o współczynniku korelacji między tymi pomiarami,
gdy nie zaokrągli się wyników przeliczenia?
gdy wynik przeliczenia zaokrągli się do pełnych cali?
Pytanie 8.9 Korelacje dodatnie i ujemne.
Korelacja między liczbą godzin, które student poświęca na naukę, a wynikiem egzaminu jest zazwyczaj .
Korelacja między temperaturą zewnętrzną a kosztami ogrzewania zimą jest .
Korelacja między rozmiarem buta a wzrostem wśród dorosłych jest zazwyczaj .
Pytanie 8.10
Korelacja między wiekiem studenta PG (obliczonym na podstawie dokładnej daty urodzenia) a jego rokiem urodzenia .
Korelacja między wiekiem studenta PG a wiekiem jego matki .
Pytanie 8.11 Spójrz na dwa wykresy rozrzutu i spróbuj podsumować to, co widzisz.
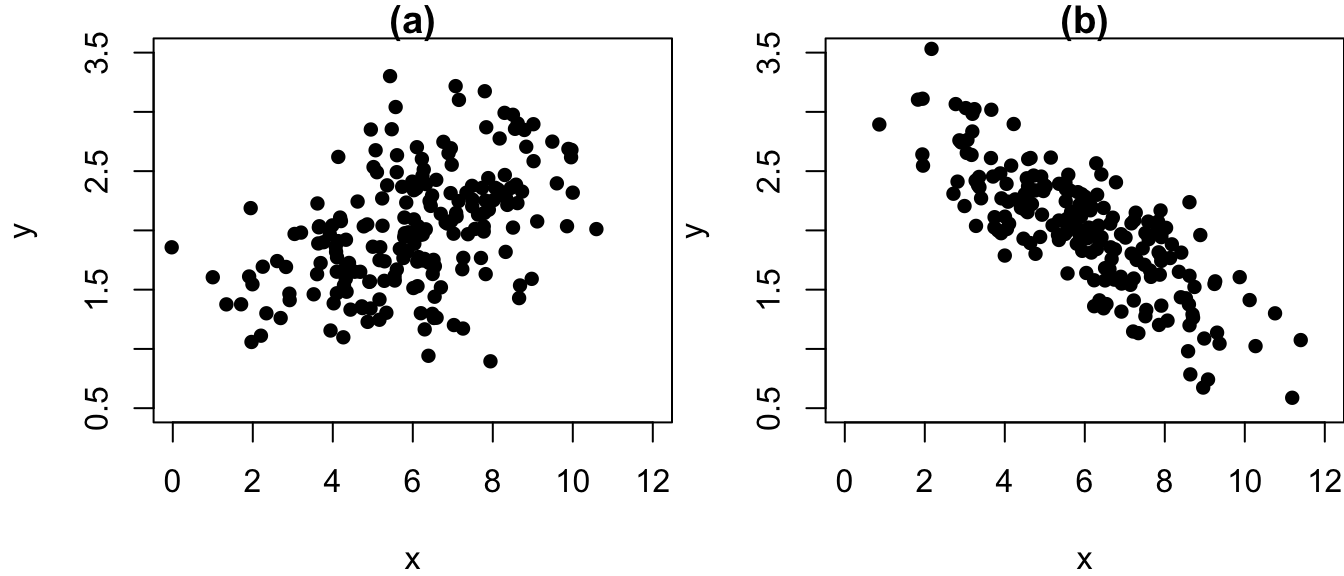
W przypadku obu wykresów średnia X wynosi około .
W przypadku obu wykresów średnia Y wynosi około .
W przypadku obu wykresów odchylenie standardowe X wynosi około .
W przypadku obu wykresów odchylenie standardowe Y wynosi około.
W przypadku wykresu (a) korelacja jest .
W przypadku wykresu (b) korelacja jest .
Silniejsza korelacja (w ujęciu bezwzględnym) jest przedstawiona na wykresie .
Pytanie 8.12 Oblicz rangi dla następującego zestawu danych:
| wartości | rangi |
|---|---|
| 30 | |
| 10 | |
| 15 | |
| 40 | |
| 60 | |
| 40 |
Pytanie 8.13 Znajdź średnie i odchylenia standardowe (\(\sigma\)) dla \(x\) i \(y\), następnie oblicz wartości standaryzowane (z-scores), a następnie użyj równania \(r(X,Y) = \frac{1}{n}\sum_{i=1}^n z_{x_i} z_{y_i}\), aby obliczyć współczynnik korelacji.
Porównaj wynik z wynikiem otrzymanym w Excelu lub w R (cor(c(2,10,8,16), c(1,1,5,5))).
\(\bar{x}\) =
\(\widehat{\sigma}_{x}\) =
\(\bar{y}\) =
\(\widehat{\sigma}_{y}\) =
| \(i\) | \(x_i\) | \(y_i\) | \(z_{x_i}\) | \(z_{y_i}\) | \(z_{x_i}\cdot z_{y_i}\) |
|---|---|---|---|---|---|
| 1 | 2 | 1 | |||
| 2 | 10 | 1 | |||
| 3 | 8 | 5 | |||
| 4 | 16 | 5 |
\(n\) =
\(r(X,Y) = \frac{1}{n}\sum_{i=1}^n z_{x_i} z_{y_i}\) =
8.9 Zadania
Zadanie 8.1 (Grima 2010) W wyborach prezydenckich w USA w 2000 roku George Bush wygrał z Alem Gore'em dzięki zwycięstwu na Florydzie różnicą mniejszą niż 1000 głosów. W pliku zawierającym wyniki głosowania według hrabstw na Florydzie sprawdź, jaka była różnica między Gore'em a Bushem pod względem całkowitej liczby głosów na Florydzie.
Zbadaj dane z wyborów prezydenckich w 2000 roku na Florydzie, dostępne w pakiecie UsingR jako zbiór danych florida. Przygotuj wykres rozrzutu z głosami Ala Gore'a (Partia Demokratyczna) na osi x i głosami Pata Buchanana (Partia Reform) na osi y. Czy zauważyłeś jakieś wartości odstające? Które hrabstwo to było? Zbadaj historię stojącą za wartością odstającą (wygoogluj ją!).
Czy zgadzasz się, że gdyby nie projekt kart do głosowania w jednym z hrabstw na Florydzie, Gore zostałby prezydentem USA w 2000 roku? Jak oszacowałbyś, ile głosów otrzymałby Gore, gdyby nie błąd popełniony przez niektórych wyborców?
Zadanie 8.2 Zastosuj równanie (8.2), aby obliczyć współczynnik korelacji Pearsona dla następującego zestawu danych:
| \(x\) | \(y\) |
|---|---|
| 1 | 3 |
| 4 | 1 |
| 5 | 4 |
| 7 | 7 |
| 13 | 5 |
Zadanie 8.3 Oblicz współczynnik korelacji Spearmana dla zestawu danych z ćwiczenia 8.2.
Zadanie 8.4 Obliczenie współczynnika korelacji Kendalla \(\tau\) dla zestawu danych z ćwiczenia 8.2.
Zadanie 8.5 Dla [danych dotyczących wzrostu ojca/syna] (https://drive.google.com/file/d/1Adx3qzXAblL4JUqgg7O3zihRxRgrQviE/view?usp=share_link):
Przygotuj wykres rozrzutu.
Oblicz korelację.
Sprawdź, czy korelacja pozostaje taka sama po zamianie zmiennych (tj. r(X, Y) = r(Y, X)).
Sprawdź, czy korelacja nie zmienia się po przeliczeniu wysokości z cali na centymetry.
Sprawdź, jak zaokrąglenie wartości (do najbliższego cala i do najbliższego centymetra) wpływa na korelację.
Zadanie 8.6 Oblicz pięcioliczbowe podsumowania (średnia X, odchylenie standardowe X, średnia Y, odchylenie standardowe Y, współczynnik korelacji między X i Y) dla następujących par zmiennych x i y pobranych z [tego zbioru danych] (https://drive.google.com/file/d/1MUcOSElfSvnIE9rJkM1Hv_x9Tf_HlE6x/view?usp=sharing):
away_x i away_y
bullseye_x i bullseye_y
dircle_x i circle_y
dino_x i dino_y
Oblicz podsumowania 5 liczb dla każdej pary i porównaj je.
Utwórz i sprawdź wykresy rozrzutu dla wszystkich par.
Co ilustruje to ćwiczenie na temat polegania wyłącznie na statystykach podsumowujących?
Zadanie 8.7 Zbadaj korelacje „małżeńskie” w zbiorze danych husband-wife.