Rozdział 2 Rozkład empiryczny cech
2.1 Szeregi statystyczne
Dane statystyczne dotyczące pojedynczej cechy przedstawione w formie tabelarycznej (lub w formie tekstu) nazywa się po polsku często szeregiem statystycznym.
2.1.1 Szereg szczegółowy
Kiedy przedstawiamy wszystkie zebrane informacje bez grupowania, np. w formie kolumny w tabeli lub listy oddzielonej przecinkami, mówimy o szeregu szczegółowym. Inna nazwa tego szeregu to szereg wyliczający. Często też mówi się w tym kontekście o „danych surowych”.
Szereg szczegółowy może dotyczyć zarówno danych jakościowych, jak i ilościowych.
Przykład:
Przypuśćmy, że zapytaliśmy ośmioro studentów o wielkość rodziny, z której pochodzą (a dokładniej, poprosiliśmy o odpowiedź na pytanie „Ile dzieci ma Twoja mama?”) i otrzymaliśmy następujące odpowiedzi:
| ID studenta | Wielkość rodziny |
|---|---|
| 1 | 1 |
| 2 | 6 |
| 3 | 2 |
| 4 | 2 |
| 5 | 3 |
| 6 | 2 |
| 7 | 2 |
| 8 | 2 |
Szereg szczegółowy możemy zapisać również w postaci listy:
1; 6; 2; 2; 3; 2; 2; 2
2.1.2 Szereg rozdzielczy punktowy
Szereg rozdzielczy to dane pogrupowane. Szereg rozdzielczy punktowy polega na przedstawieniu wszystkich możliwych wartości zmiennej wraz z liczebnością (tzn. informacją, ile razy dana wartość wystąpiła).
Szereg rozdzielczy punktowy może dotyczyć zarówno cech jakościowych, jak i ilościowych dyskretnych.
W przypadku szeregu rozdzielczego punktowego nie następuje utrata informacji, tzn. jesteśmy w stanie odtworzyć szereg szczegółowy.
Przykłady:
| Wielkość rodziny | Liczba respondentów |
|---|---|
| 1 | 14 |
| 2 | 59 |
| 3 | 10 |
| 4 | 6 |
| 5 | 1 |
| 6 | 1 |
| Obwód klatki piersiowej w calach | Liczba obserwacji |
|---|---|
| 33 | 3 |
| 34 | 18 |
| 35 | 81 |
| 36 | 185 |
| 37 | 420 |
| 38 | 749 |
| 39 | 1073 |
| 40 | 1079 |
| 41 | 934 |
| 42 | 658 |
| 43 | 370 |
| 44 | 92 |
| 45 | 50 |
| 46 | 21 |
| 47 | 4 |
| 48 | 1 |
2.1.3 Szereg rozdzielczy przedziałowy
Szereg rozdzielczy przedziałowy to przedstawienie przedziałów wartości wraz z podaną liczebnością.
W przypadku szeregu rozdzielczego przedziałowego następuje utrata informacji; nie jesteśmy w stanie odtworzyć szeregu szczegółowego z szeregu przedziałowego. Szereg rozdzielczy można sporządzać dla cech ilościowych.
Na podstawie szeregu rozdzielczego przedziałowego można stworzyć histogram.
Przykład:
| Przedział | Liczba spraw |
|---|---|
| do 15 dni | 161 328 |
| powyżej 15 dni do 1 mies. | 118 435 |
| powyżej 1 do 2 mies. | 265 533 |
| powyżej 2 do 3 mies. | 263 151 |
| powyżej 3 do 6 miesięcy | 309 985 |
| powyżej 6 do 12 miesięcy | 141 561 |
| powyżej 12 miesięcy do 2 lat | 68 070 |
| powyżej 2 do 3 lat | 23 978 |
| powyżej 3 do 5 lat | 11 973 |
| powyżej 5 do 8 lat | 3 911 |
| ponad 8 lat | 2 305 |
2.2 Wizualizacja cech jakościowych
Wizualizacja zmiennych jakościowych pomaga podsumować, jak obserwacje rozkładają się pomiędzy poszczególne kategorie.
Poniżej przedstawiono kilka popularnych form graficznych: wykresy słupkowe, skumulowane wykresy słupkowe oraz wykresy kołowe.
2.2.1 Wykresy słupkowe
Wykresy słupkowe przedstawiają zwykle liczebność (lub częstość, udział) obserwacji w każdej kategorii. Wykresy słupkowe mogą być pionowe lub poziome. Czasem (np. w Microsoft Excel) wykresy z pionowymi słupkoami nazywa się wykresami kolumnowymi.
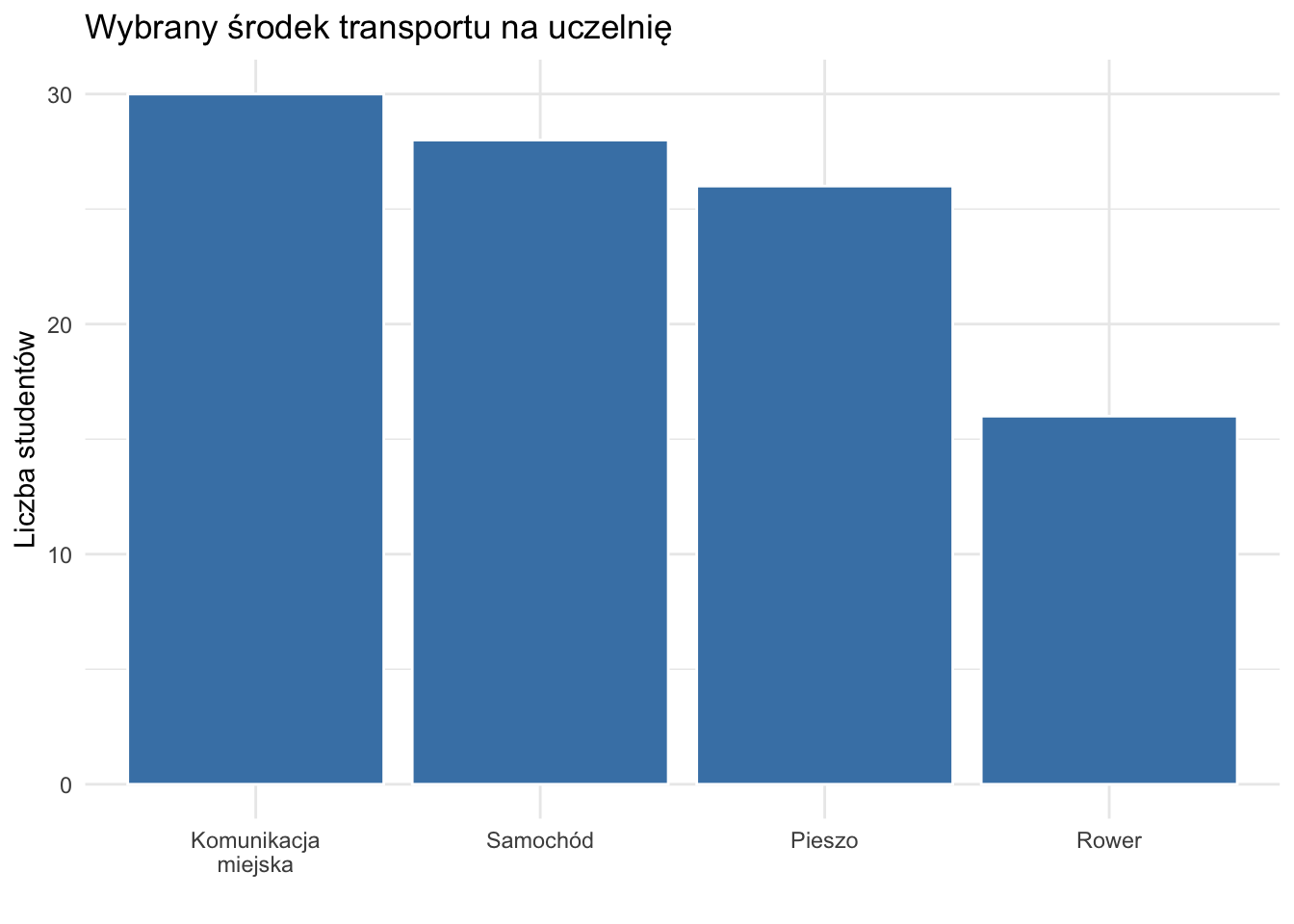
Rysunek 2.1: Przykład wykresu przestawiającego środek transportu na uczelnię wybierany przez studentów.
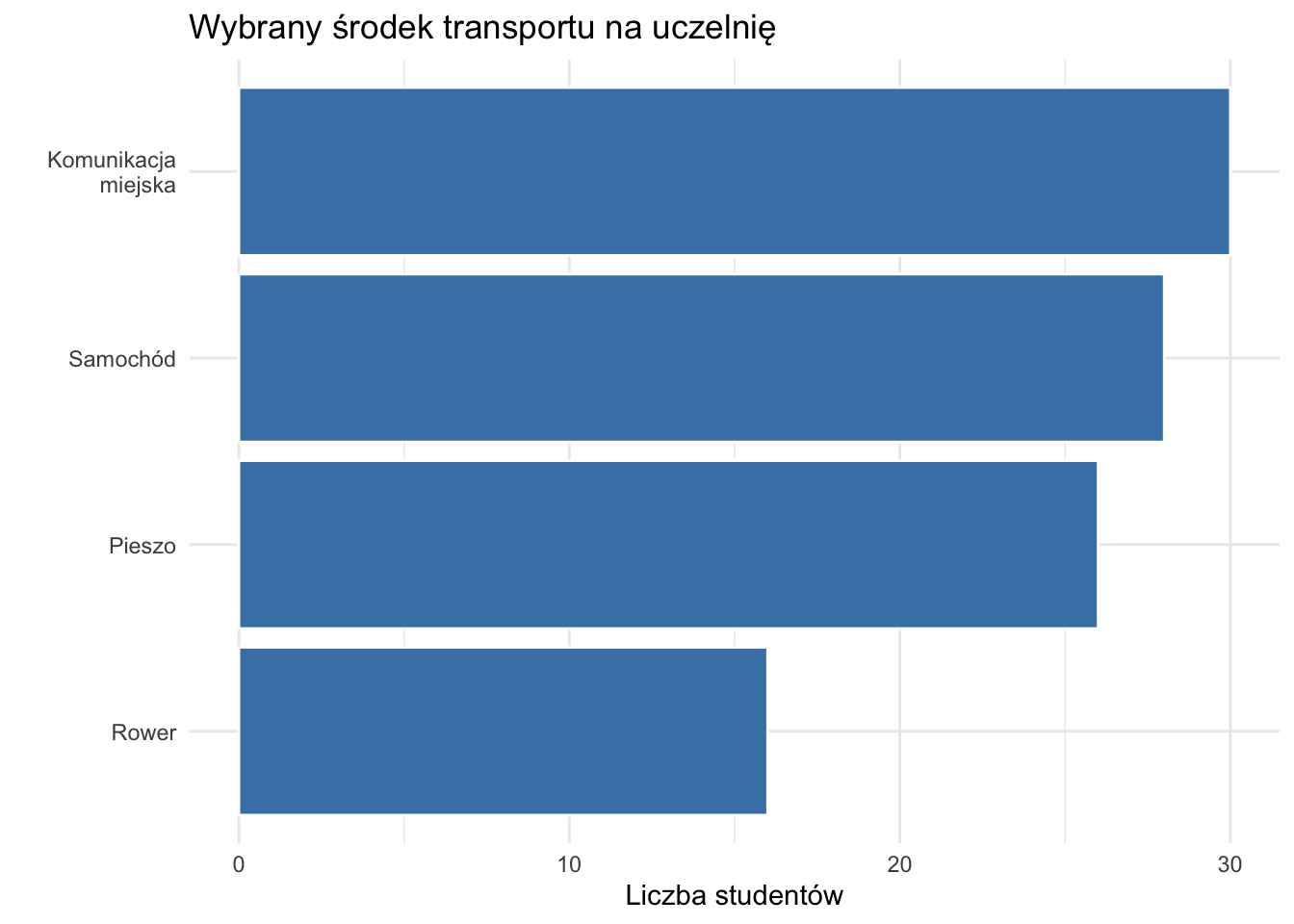
Rysunek 2.2: Wersja pozioma wykresu przestawiającego środek transportu na uczelnię wybierany przez studentów.
2.2.2 Skumulowane wykresy słupkowe
Skumulowane wykresy słupkowe umożliwiają jednoczesną wizualizację dwóch zmiennych jakościowych, pokazując zarówno strukturę (skład), jak i porównanie między grupami.
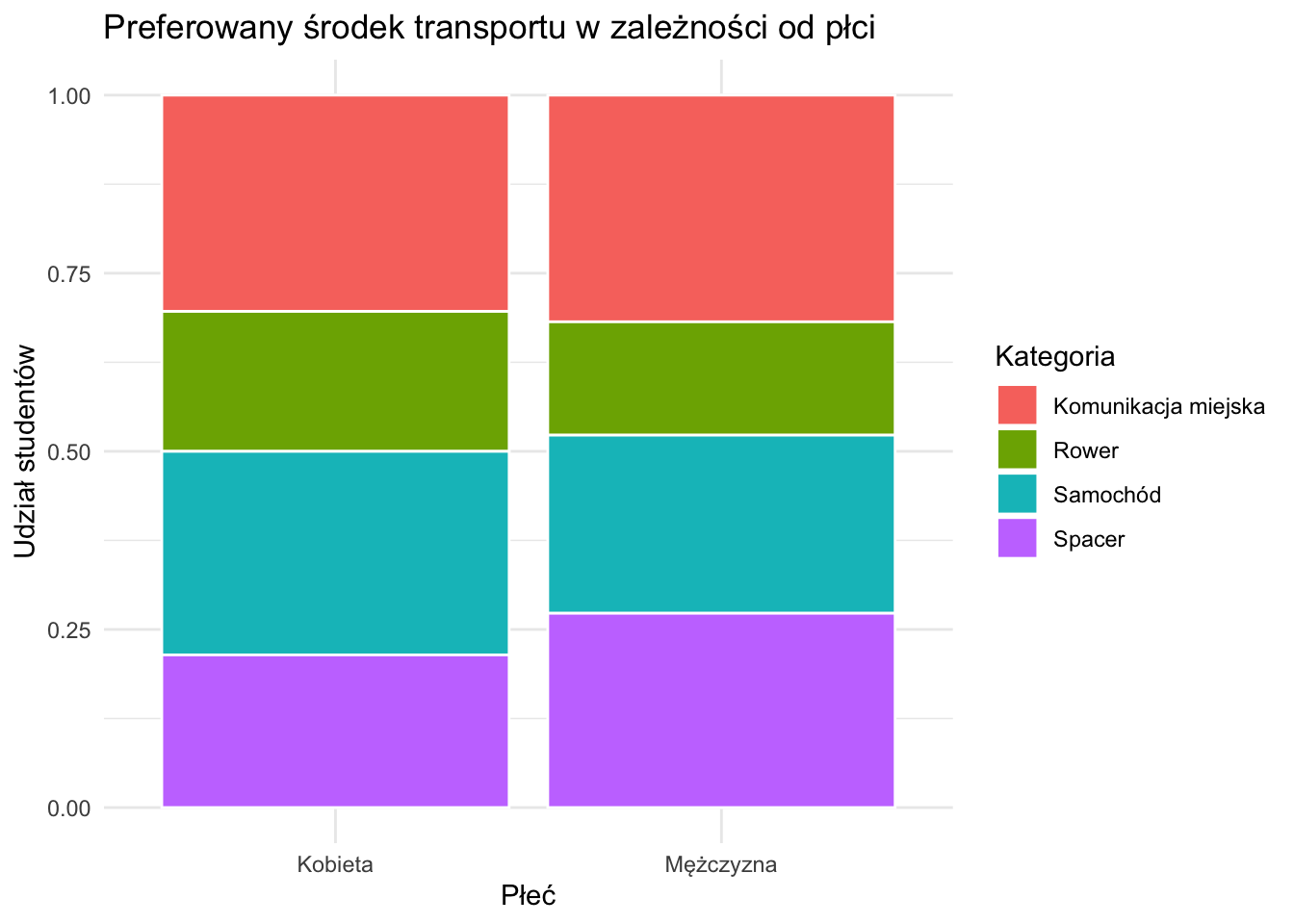
Rysunek 2.3: Przykład skumulowanego wykresu słupkowego.
2.2.3 Wykresy kołowe
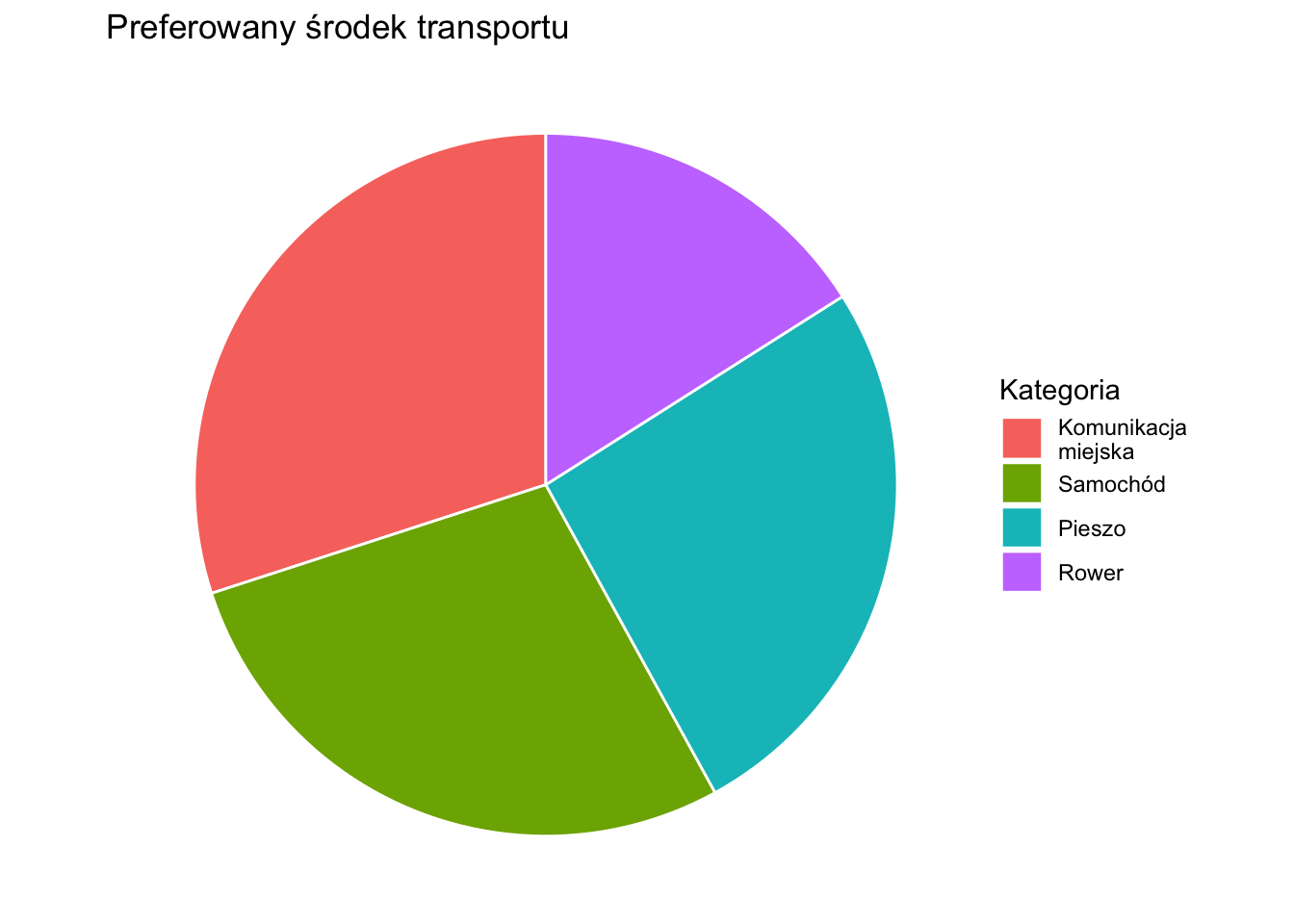
Rysunek 2.4: Przykład wykresu kołowego.
Wykresy kołowe zazwyczaj nie są zalecane. Zdaniem specjalistów od wizualizacji danych utrudniają one dokładne porównywanie wielkości kategorii — nasz wzrok znacznie lepiej ocenia długości (jak na wykresach słupkowych) niż kąty czy pola powierzchni. Gdy kategorii jest wiele lub różnice między nimi są niewielkie, poprawna interpretacja udziałów poszczególnych kategorii staje się niemal niemożliwa. W przeciwieństwie do tego wykresy słupkowe umożliwiają łatwe porównywanie kategorii i mogą w czytelny sposób przedstawiać zarówno liczebności, jak i udziały procentowe. Tym samym, chociaż wykresy kołowe sprawdzają się w prostych prezentacjach z kilkoma kategoriami, wykresy słupkowe są na ogół skuteczniejszym narzędziem analizy i porównań.
2.3 Histogram – wizualizacja rozkładu cechy ilościowej
Histogram to wykres, który pozwala poznać kształt rozkładu cechy ilościowej. Stworzenie histogramu wymaga wcześniejszego pogrupowania obserwacji w przedziały klasowe (czyli przygotowania szeregu rozdzielczego przedziałowego). Przedziały zaznacza się na osi X. Dla tak utworzonych przedziałów wyznacza się liczebność obserwacji w poszczególnych przedziałach.
Przedziały są zwykle równej szerokości, jednak jest możliwe przygotowanie przedziałów, których szerokości będą się różnić.
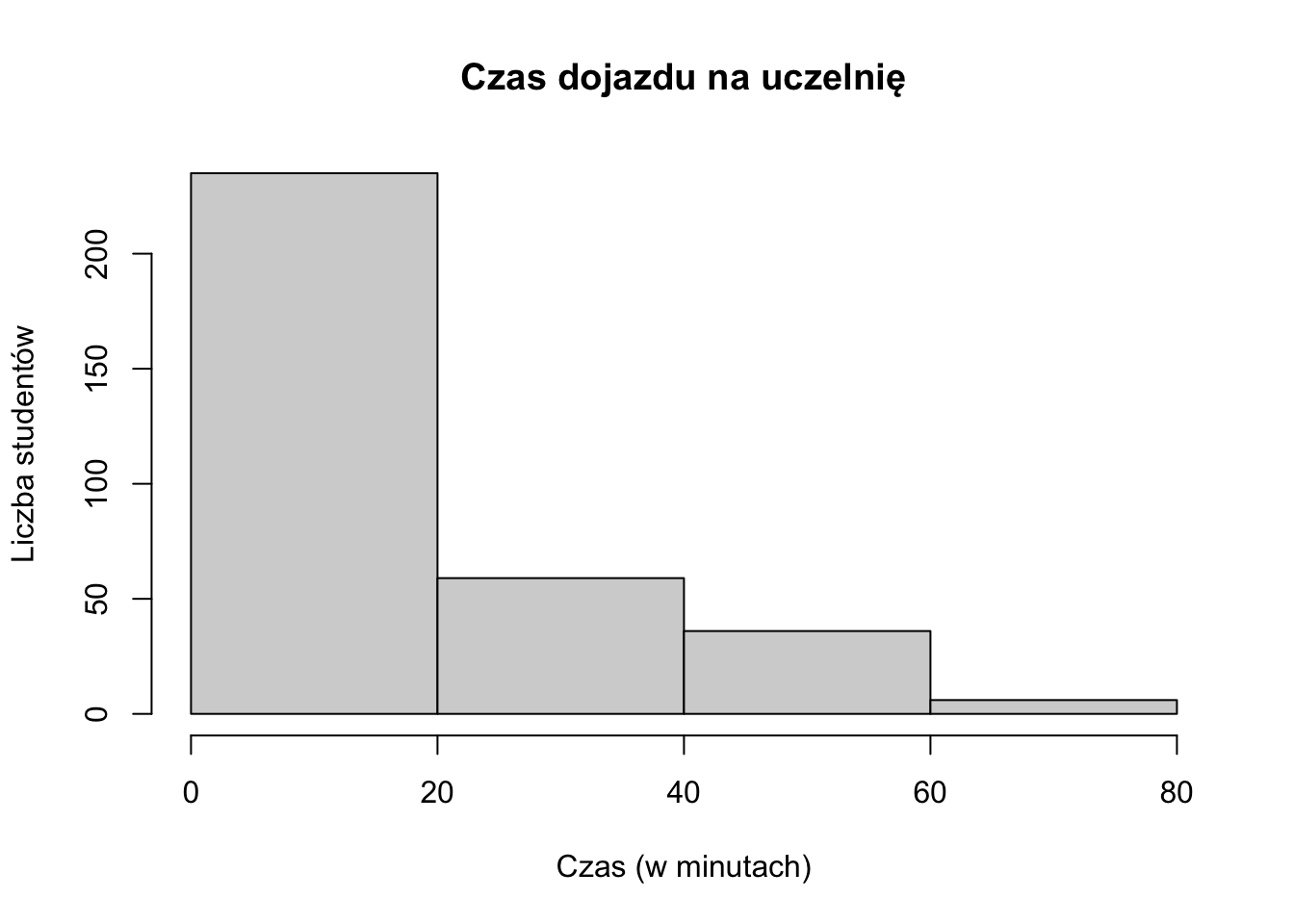
Rysunek 2.5: Przykład histogramu z równymi przedziałami.
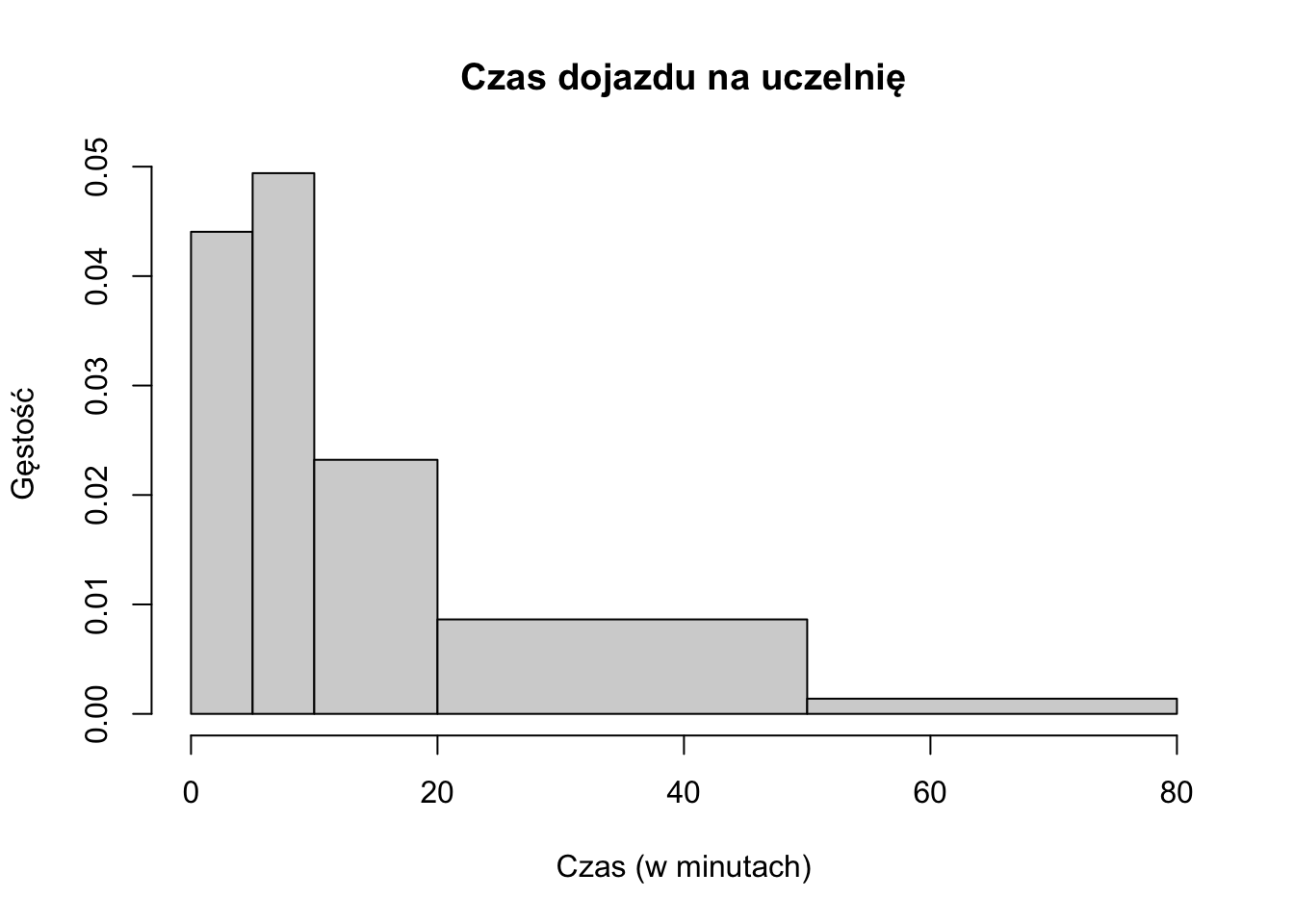
Rysunek 2.6: Przykład histogramu z nierównymi przedziałami.
2.3.1 Co jest na osi Y?
W histogramie znaczenie mają pola prostokątów, z których się składa, a ich wysokość jest kwestią wtórną. Jeżeli szerokości przedziałów klasowych są równe, na osi Y mogą znaleźć się po prostu liczebności (w sytuacji równych szerokości przedziałów pola prostokątów są wprost proporcjonalne do ich wysokości) lub udziały w łącznej liczebności zbiorowości (wyrażone jako ułamek lub procent). Jeżeli szerokości przedziałów klasowych histogramu nie są równe, na osi Y nie mogą znaleźć się liczebności, w takiej sytuacji na osi Y najczęściej przedstawia się tzw. gęstość częstości (ang. frequency density).
Rysunek 2.6 przedstawia histogram z nierównymi przedziałami. W tabeli 2.5 zilustrowana sposób obliczenia wartości gęstości potrzebnych do prawidłowego narysowania histogramu.
| Przedział | Liczba obserwacji | Częstość względna | Szerokość przedziału | Gęstość ( = Częstość względna / Szerokość przedziału) |
|---|---|---|---|---|
| (0;5] | 74 | 0,2202381 | 5 | 0,0440476 |
| (5;10] | 83 | 0,2470238 | 5 | 0,0494048 |
| (10;20] | 78 | 0,2321429 | 10 | 0,0232143 |
| (20;50] | 87 | 0,2589286 | 30 | 0,0086310 |
| (50;80] | 14 | 0,0416667 | 30 | 0,0013889 |
2.3.2 Kształty histogramów
Typowe kształty histogramów:
- rozkład (w przybliżeniu) symetryczny, jednomodalny
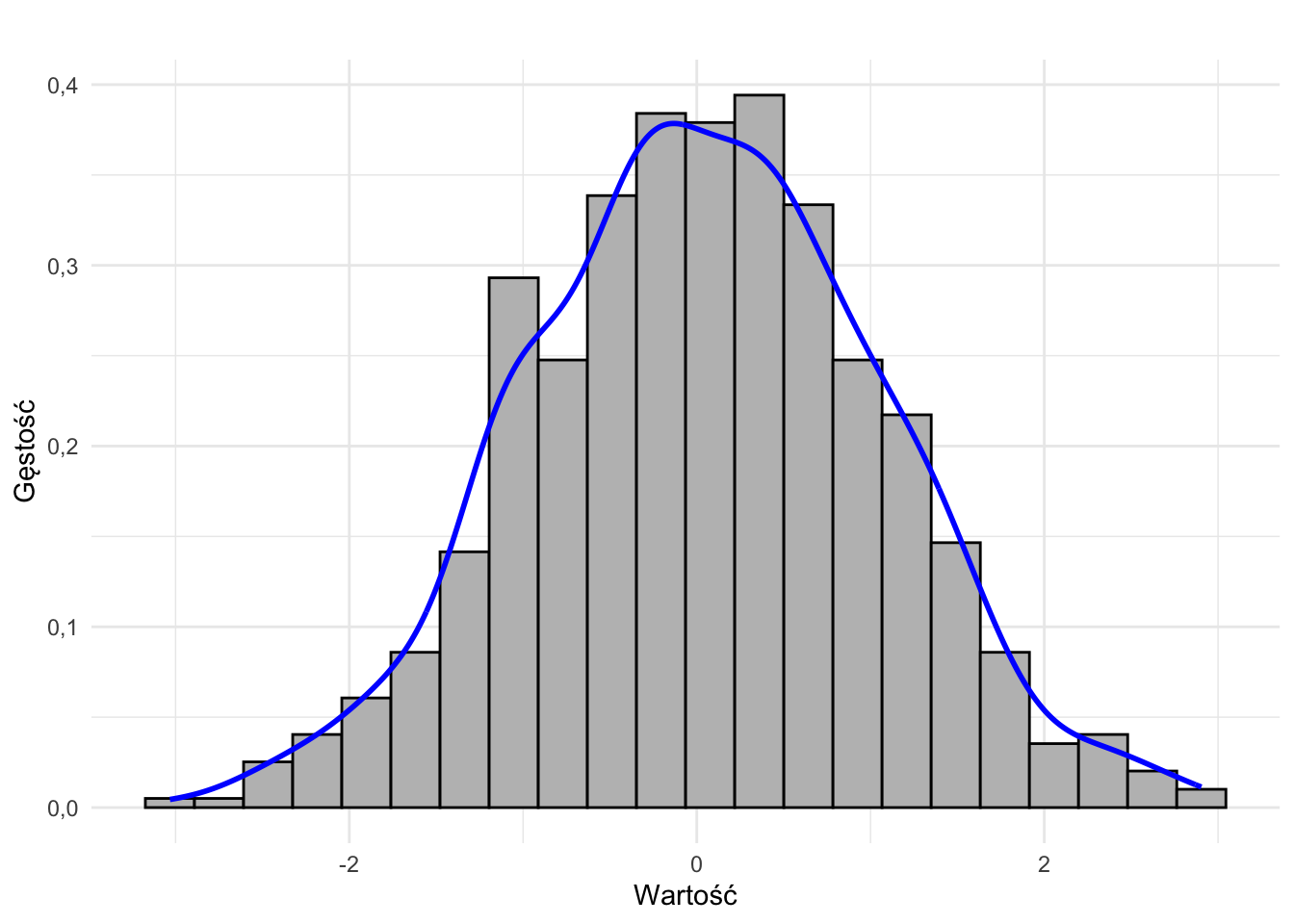
- rozkład prawostronnie skośny
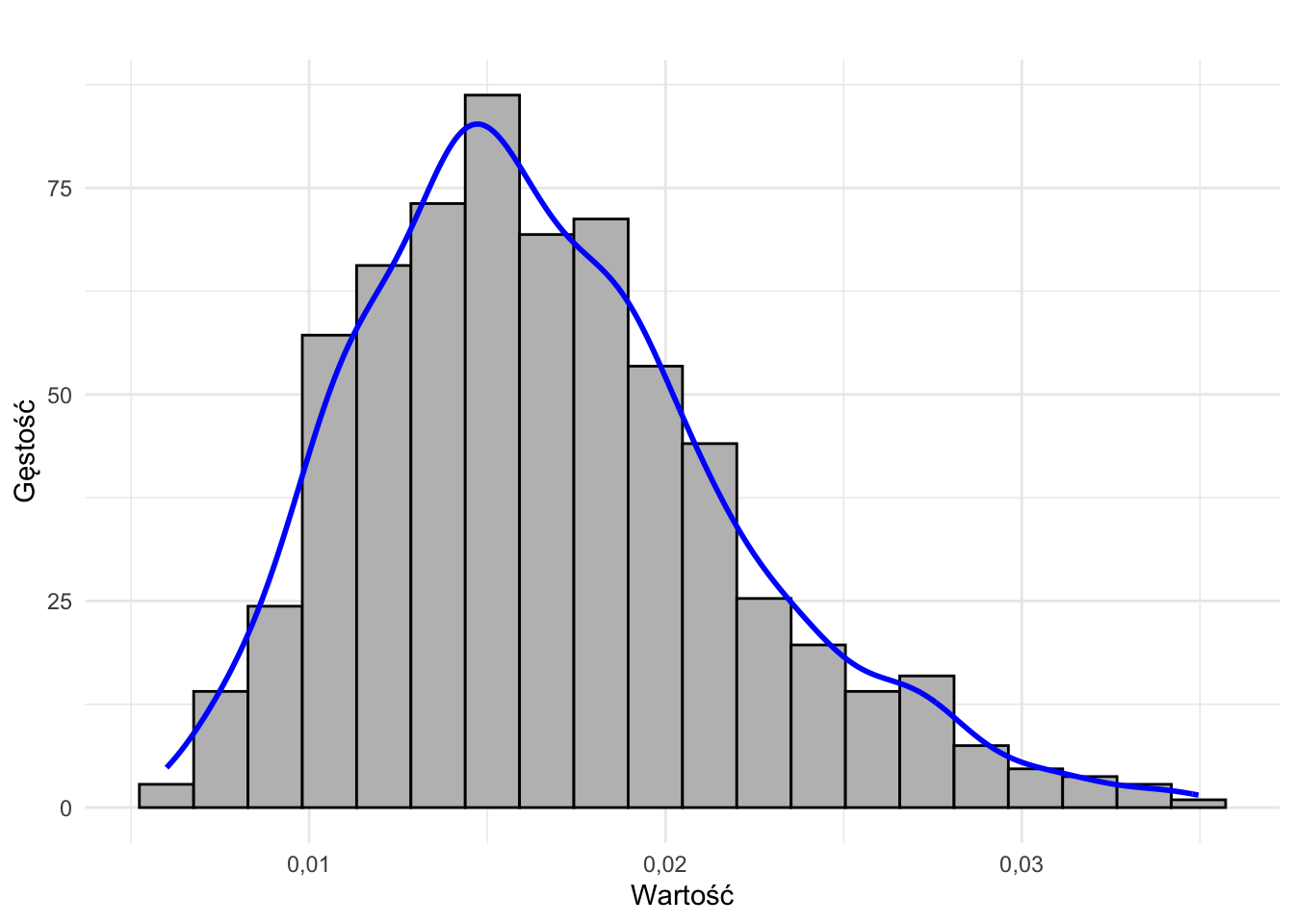
- rozkład skrajnie (prawostronnie) asymetryczny
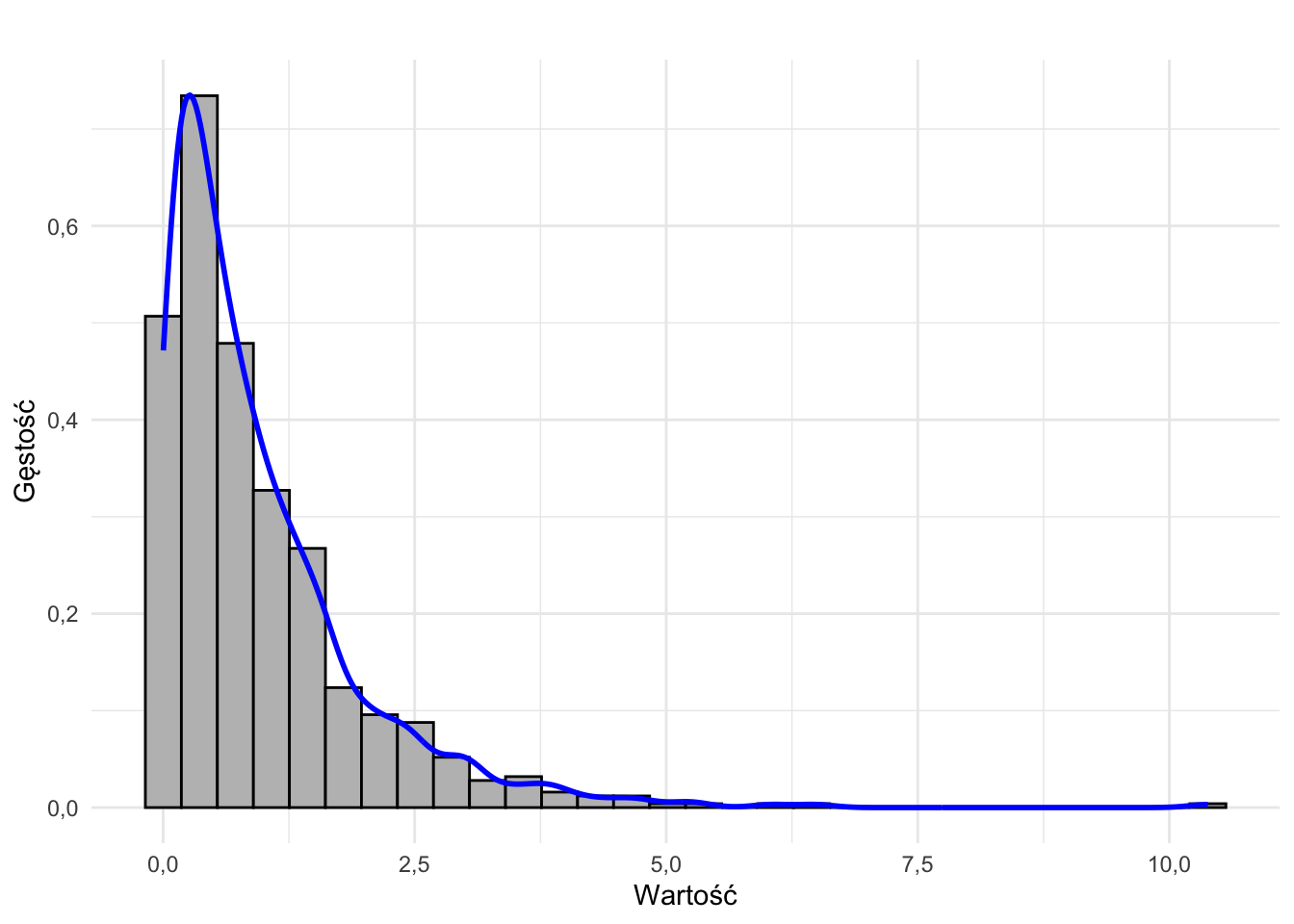
- rozkład lewostronnie skośny
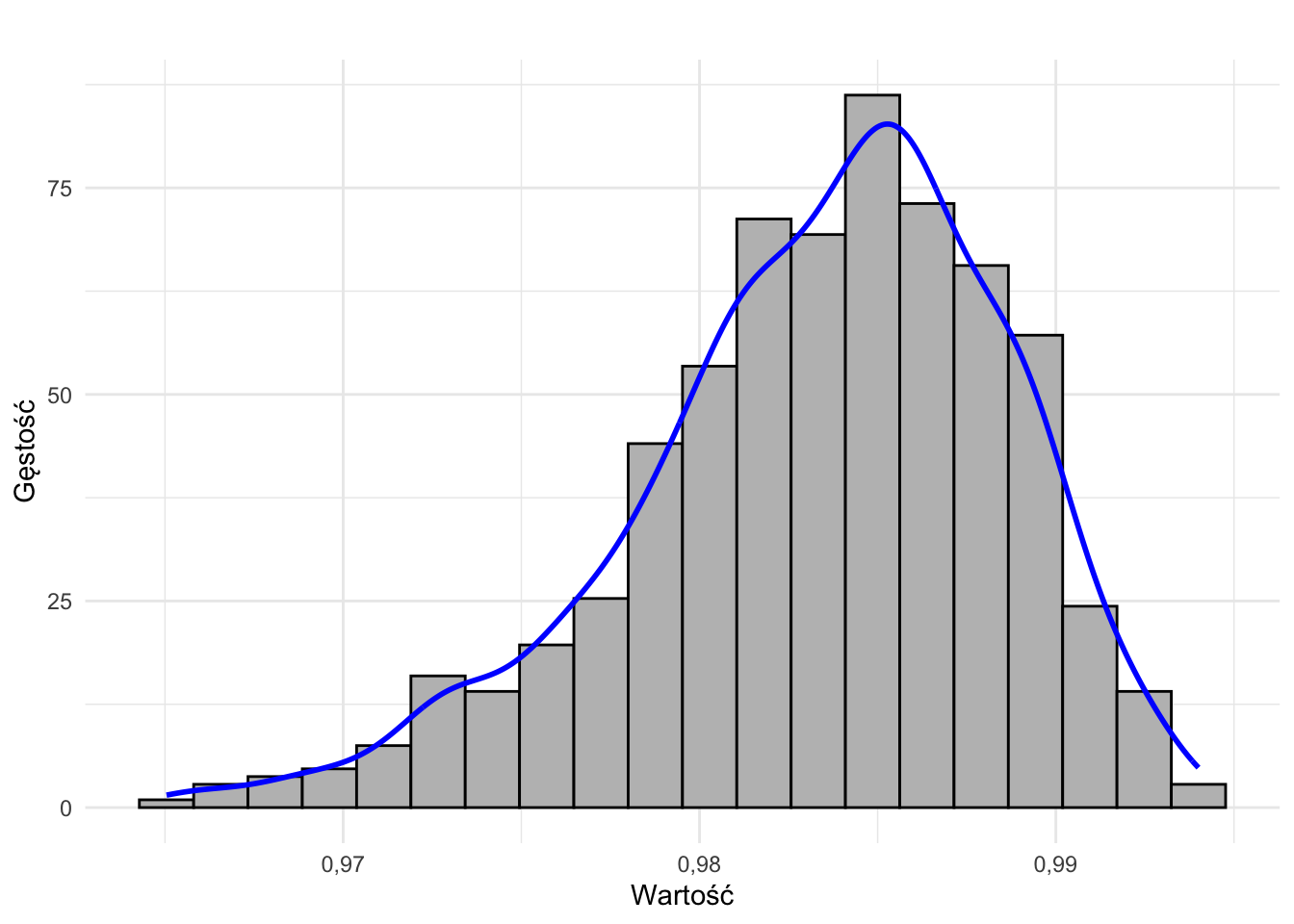
- rozkład dwumodalny
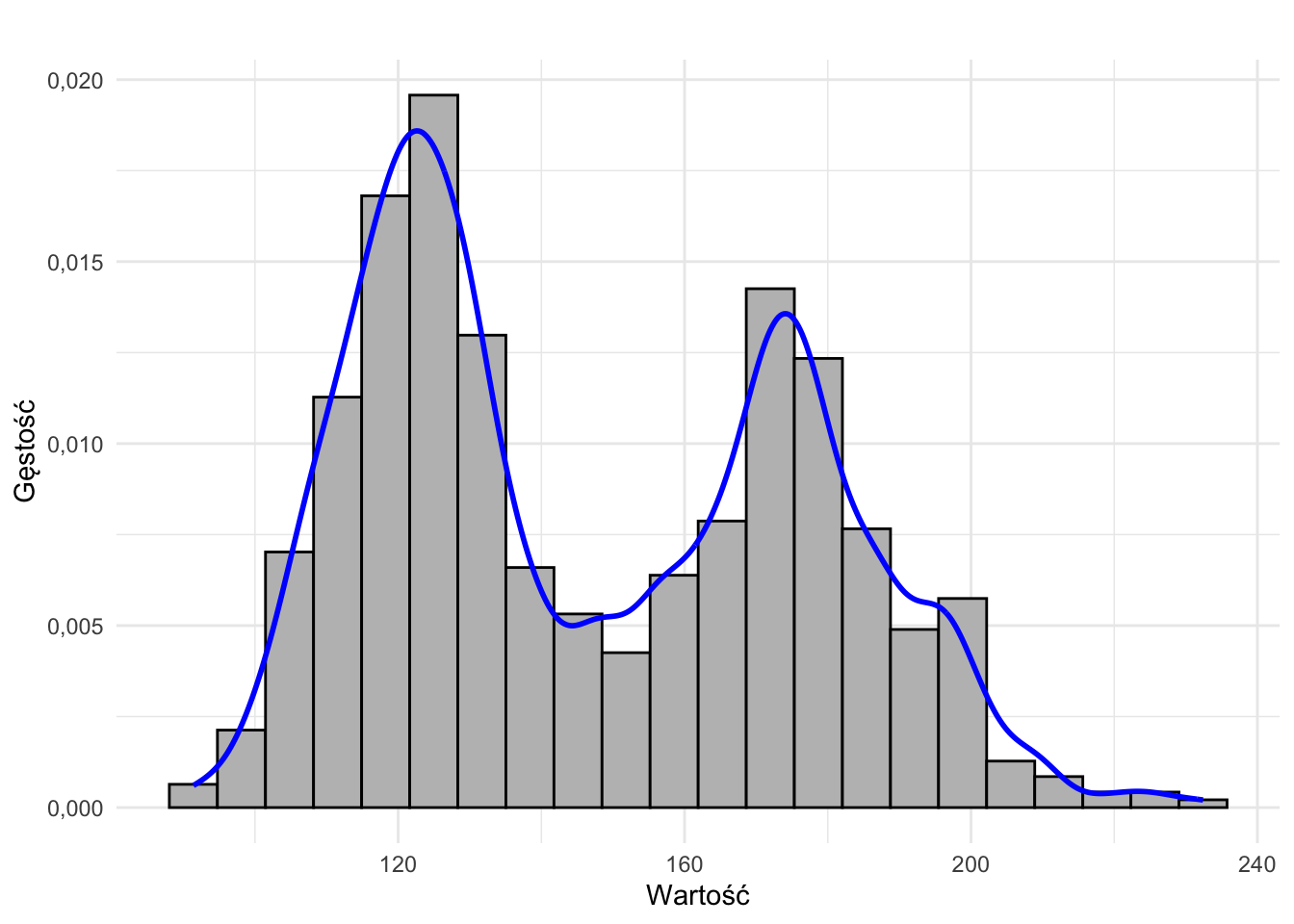
- rozkład równomierny (jednostajny)
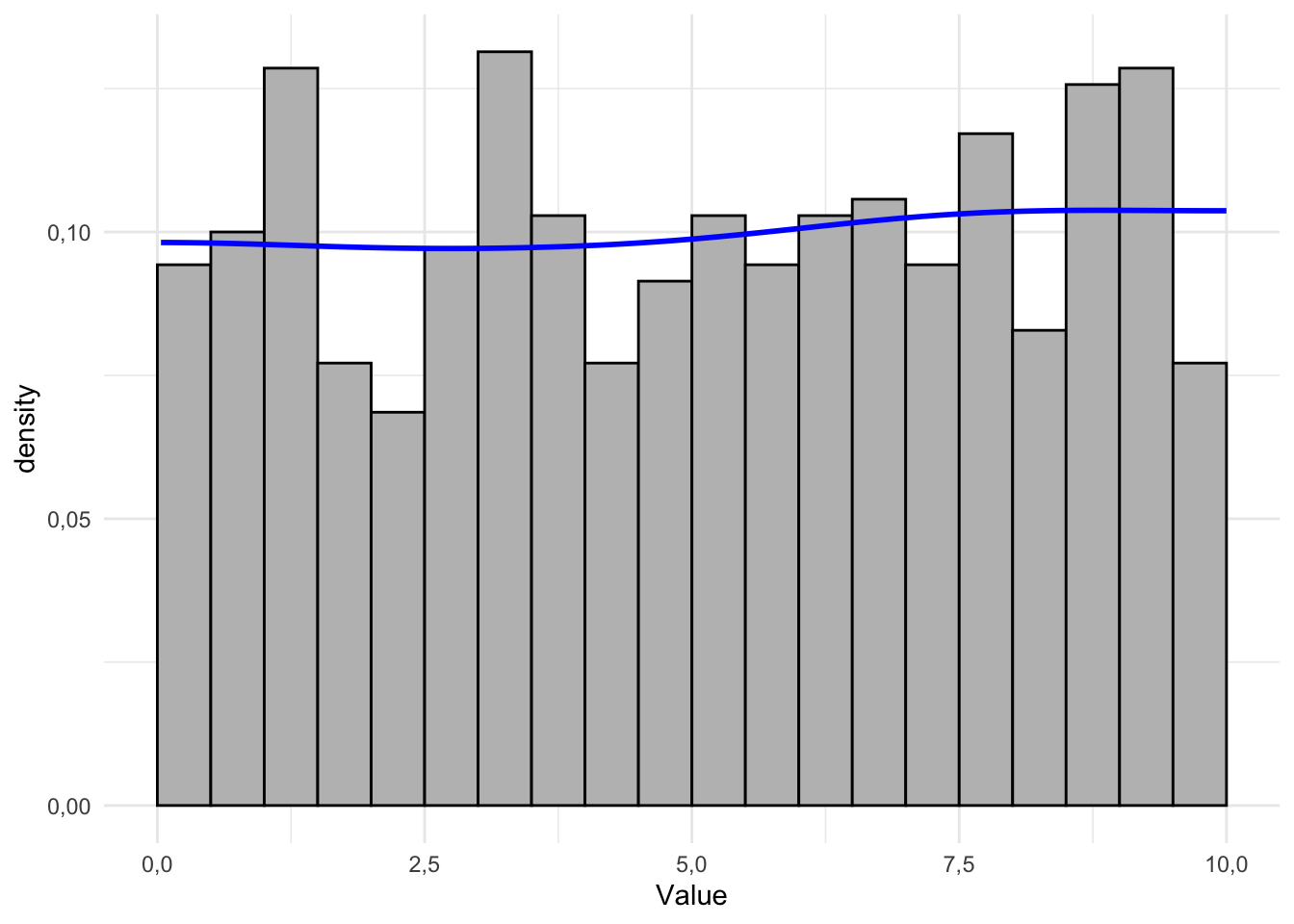
2.3.3 Histogramy a wykresy słupkowe
Niektórzy uważają histogramy za szczególny przypadek wykresów słupkowych, niemniej jednak można powiedzieć, że są to dwa różne byty:
Histogram
zawsze dotyczy cechy ilościowej,
zawsze pokazuje rozkład cechy,
używa przedziałów klasowych (zmienna, której rozkład przedstawia, jest pogrupowana w uporządkowane przedziały),
składa się z prostokątów (słupków), które zwykle przylegają do siebie.
Wykres słupkowy
prezentuje dane za pomocą słupków,
może przedstawiać rozkład zmiennej jakościowej (liczebności lub udział poszczególnych kategorii),
może służyć do porównywania kategorii lub jednostek między sobą (np. średnie dochody w trzech grupach pracowniczych),
może pokazywać wartości cechy w czasie.
2.3.4 Liczba przedziałów klasowych
Istnieją różne reguły dotyczące liczby przedziałów klasowych lub (co jest ściśle powiązane) ich szerokości.
Należą do nich na przykład:
- Reguła pierwiastka kwadratowego
\[k=\sqrt{n} \tag{2.1}\]
gdzie:
\(k\) = liczba przedziałów
\(n\) = liczba obserwacji
- Reguła Sturgesa
\[k=1+log_2(n) \tag{2.2}\]
- Reguła Freedmana-Diaconisa
\[\text{Szerokość przedziału}=\frac{2\cdot IQR}{\sqrt[3]{n}} \tag{2.3}\]
gdzie IQR oznacza rozstęp międzykwartylowy (zob. 4.2).
- Reguła Scotta
\[\text{Szerokość przedziału}=\frac{3\cdot s}{\sqrt[3]{n}} \tag{2.4}\]
gdzie \(s\) jest odchyleniem standardowym z próby.
Najważniejszą regułą jest jednak reguła „wzrokowa”. Histogram musi dobrze wyglądać: przedziały nie mogą być ani za szerokie (będzie ich wtedy zbyt mało), ani za wąskie (zbyt liczne).
2.4 Jądrowy estymator gęstości
Jądrowy estymator gęstości to gładka krzywa pokazująca, w których wartościach danych obserwacje pojawiają się częściej, a w których rzadziej2. W przeciwieństwie do histogramów, które mają schodkową postać i zależą od szerokości oraz położenia przedziałów, wykresy gęstości jądrowej zapewniają ciągłą i często bardziej estetyczną wizualnie reprezentację rozkładu. Można je traktować jako wygładzone wersje histogramów, pomagające lepiej zobaczyć ogólny kształt rozkładu danych.
Wykresy gęstości jądrowej są szczególnie przydatne do identyfikowania dominanty oraz skośności danych.
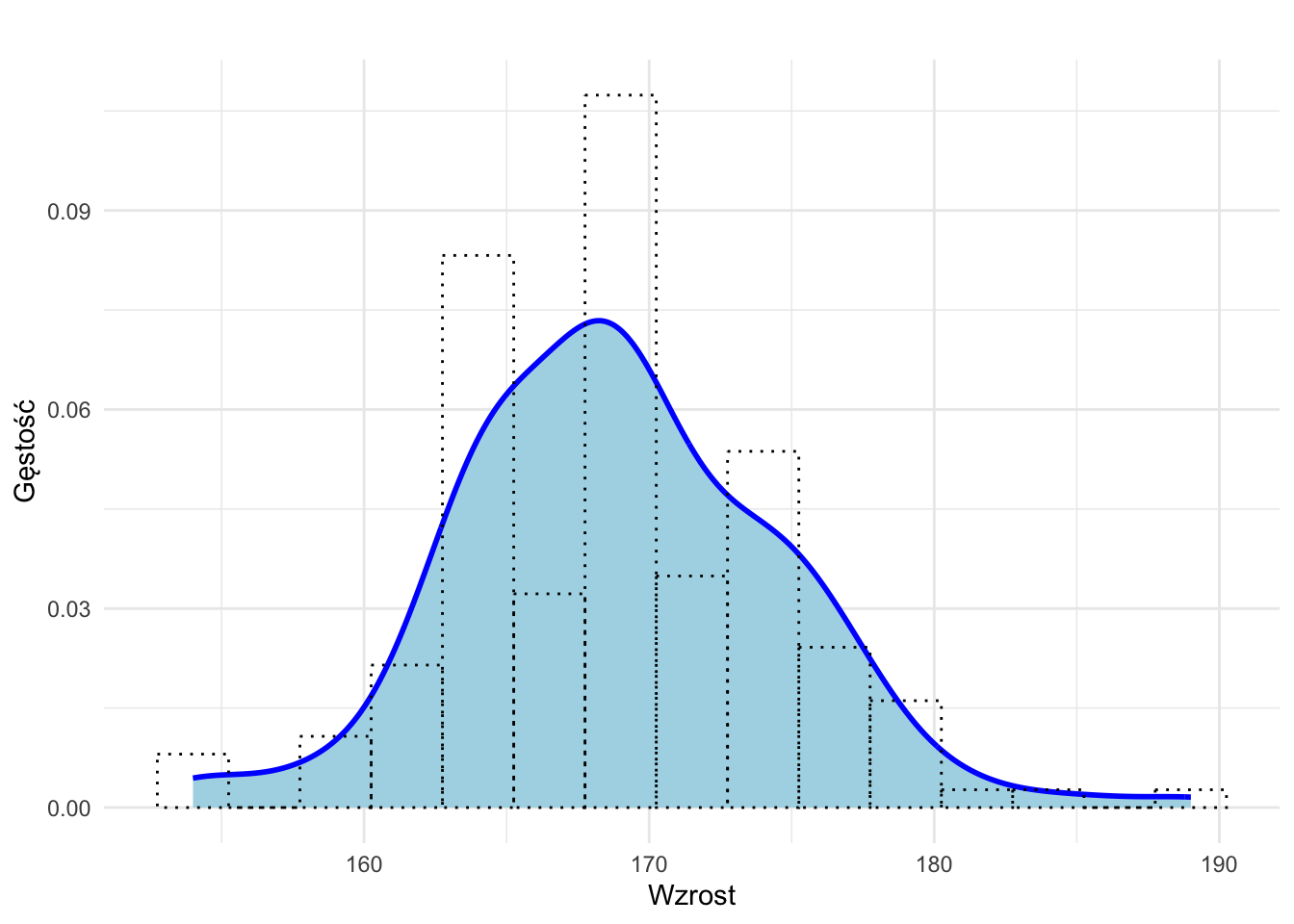
Rysunek 2.7: Przykład wykresu gęstości ilustrującego wzrost studentek na kursie statystyki nałożonego na histogram przedstawiający te same dane.
2.5 Wykres skrzypcowy
Wykres skrzypcowy to kolejny rodzaj wykresu stosowany do prezentowania i porównywania rozkładów danych ilościowych. Pojedynczy rozkład na wykresie skrzypcowym jest przedstawiony jako dwa identyczne estymatory jądrowe gęstości, odbite lustrzanie względem pionowej lub poziomej osi symetrii, a następnie połączone ze sobą. Nazwa wykresu pochodzi od domniemanego podobieństwa jego kształtu do skrzypiec.
Wykresy skrzypcowe są szczególnie przydatne do porównywania rozkładów pomiędzy różnymi grupami.
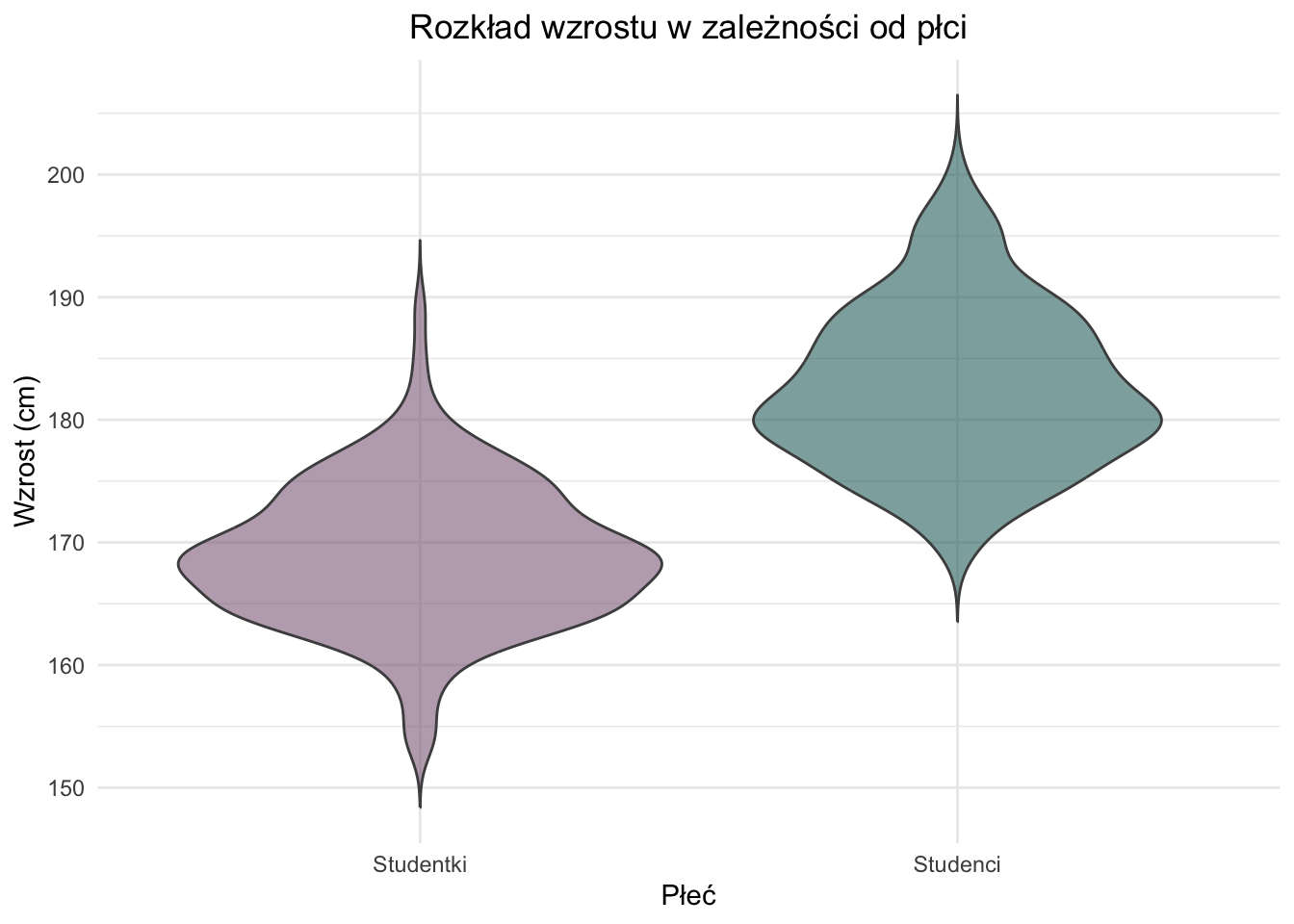
Rysunek 2.8: Przykładowe wykresy skrzypcowe umożliwiające porównanie wzrostu studentów i studentek.
2.6 Dystrybuanta empiryczna
Dystrybuanta empiryczna (ang. empirical cumulative distribution function, ECDF) przedstawia odsetek obserwacji mniejszych lub równych danej wartości.
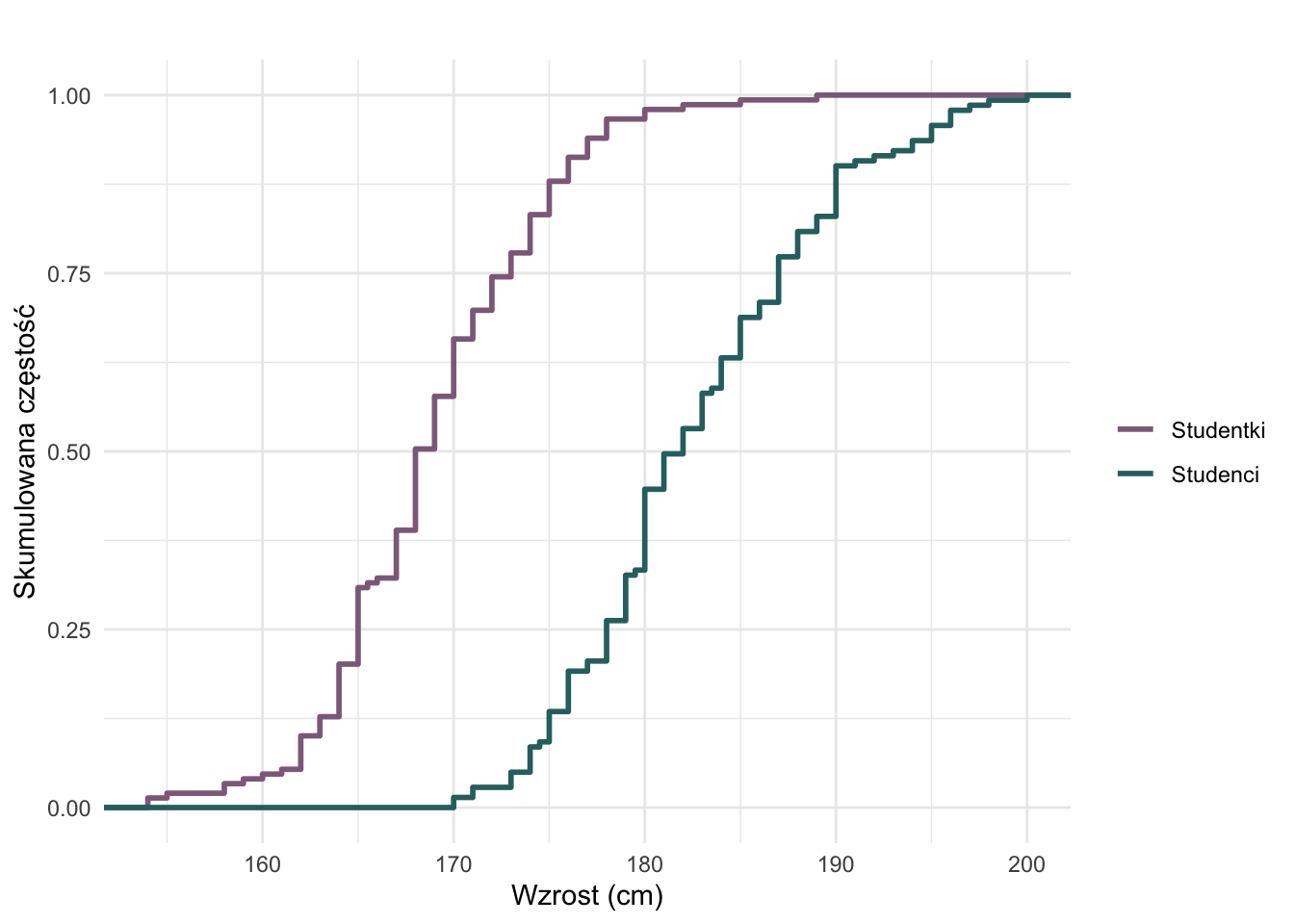
Rysunek 2.9: Empiryczna dystrybuanta wzrostu według płci.
2.7 Linki
Histogram — jak liczba/szerokość przedziałów klasowych wpływa na histogram? Symulacja internetowa: https://college.cengage.com/nextbook/statistics/utts_13540/student/html/simulation2_1.html
2.8 Zadania
Zadanie 2.1 Wykorzystując dane z pliku SpeedRadarData.csv sporządź histogram przedstawiający prędność jednośladów w okolicach radaru. Z czego może wynikać kształt histogramu? Jak się nazywa taki kształt rozkładu?
Dane pochodzą z tego wpisu na Facebooku.
Zadanie 2.2 (Freedman, Pisani, and Purves 2007) Wykres przedstawia rozkład rodzin według dochodów w Stanach Zjednoczonych w 1973 r.
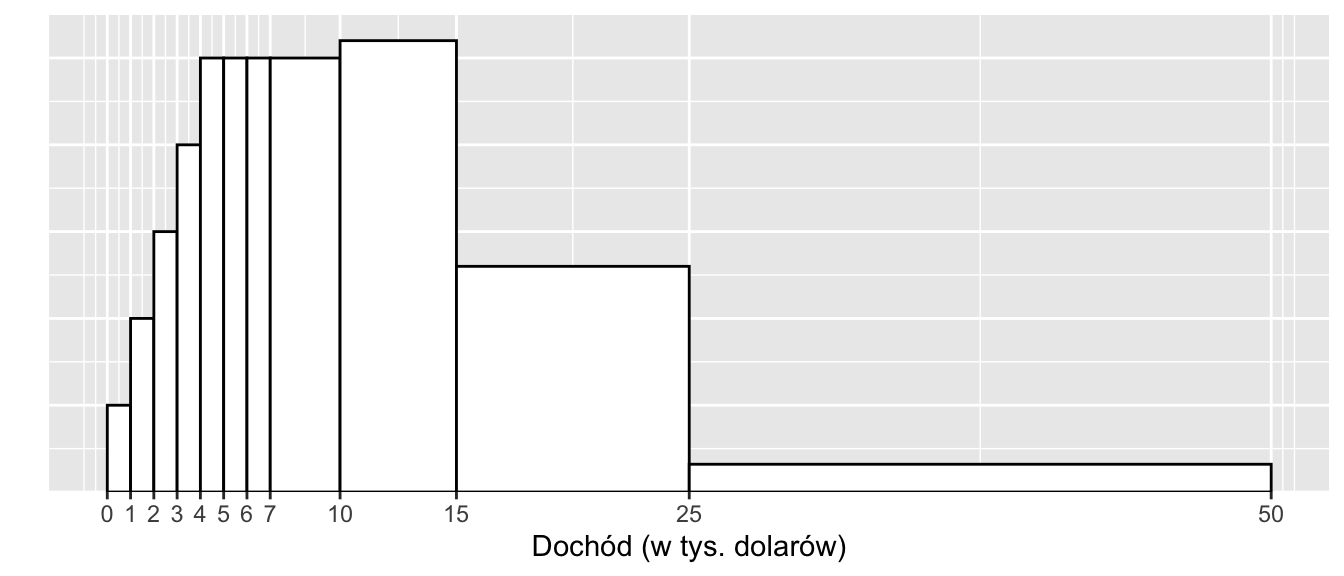
Około 1% rodzin przedstawionych na wykresie miało dochody od 0 do 1000 dolarów. Oszacuj odsetek rodzin, które miały dochody:
- od 1000 do 2000 dolarów: %
- od 2000 do 3000 dolarów: %
- od 3000 do 4000 dolarów: %
- od 4000 do 5000 dolarów: %
- od 4000 do 7000 dolarów: %
- od 7000 do 10000 dolarów: %
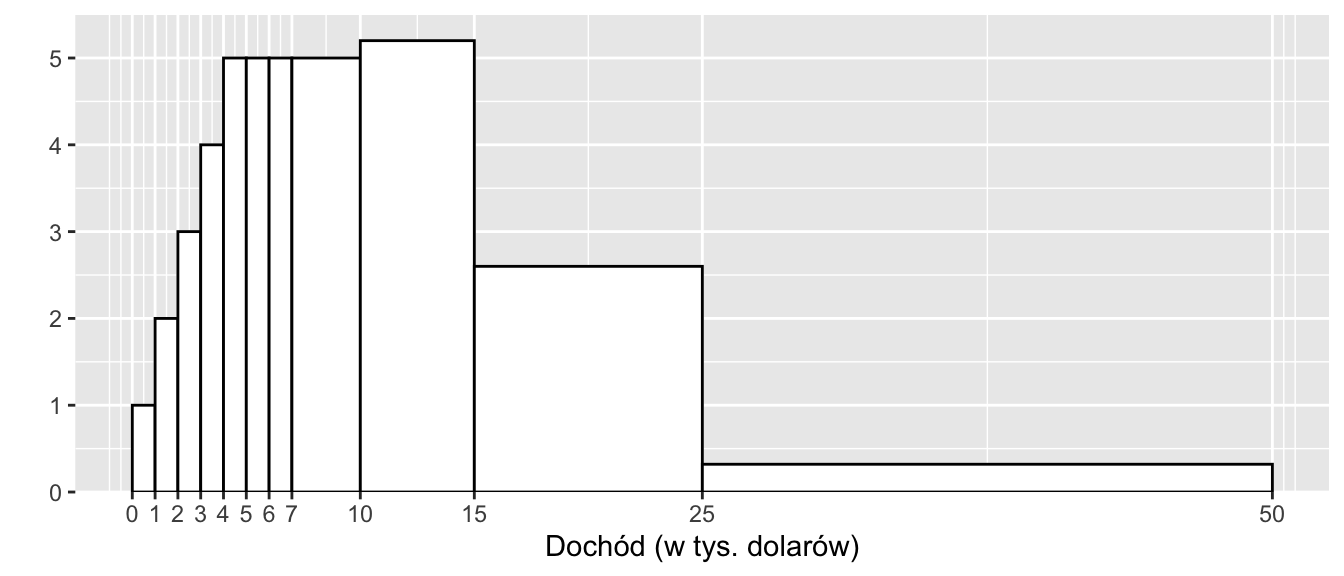
- Do powyższego histogramu dodano skalę osi Y. Liczby (wysokość słupków) pokazują:
- Czy było więcej rodzin zarabiających od 10 000 do 11 000 dolarów, czy od 15 000 do 16 000 dolarów? A może liczby były mniej więcej takie same? Co sugeruje wykres.
Zadanie 2.3 (Freedman, Pisani, and Purves 2007) Poniższy histogram przedstawia rozkład wyników egzaminów końcowych ze statystyki w pewnej grupie studenckiej.
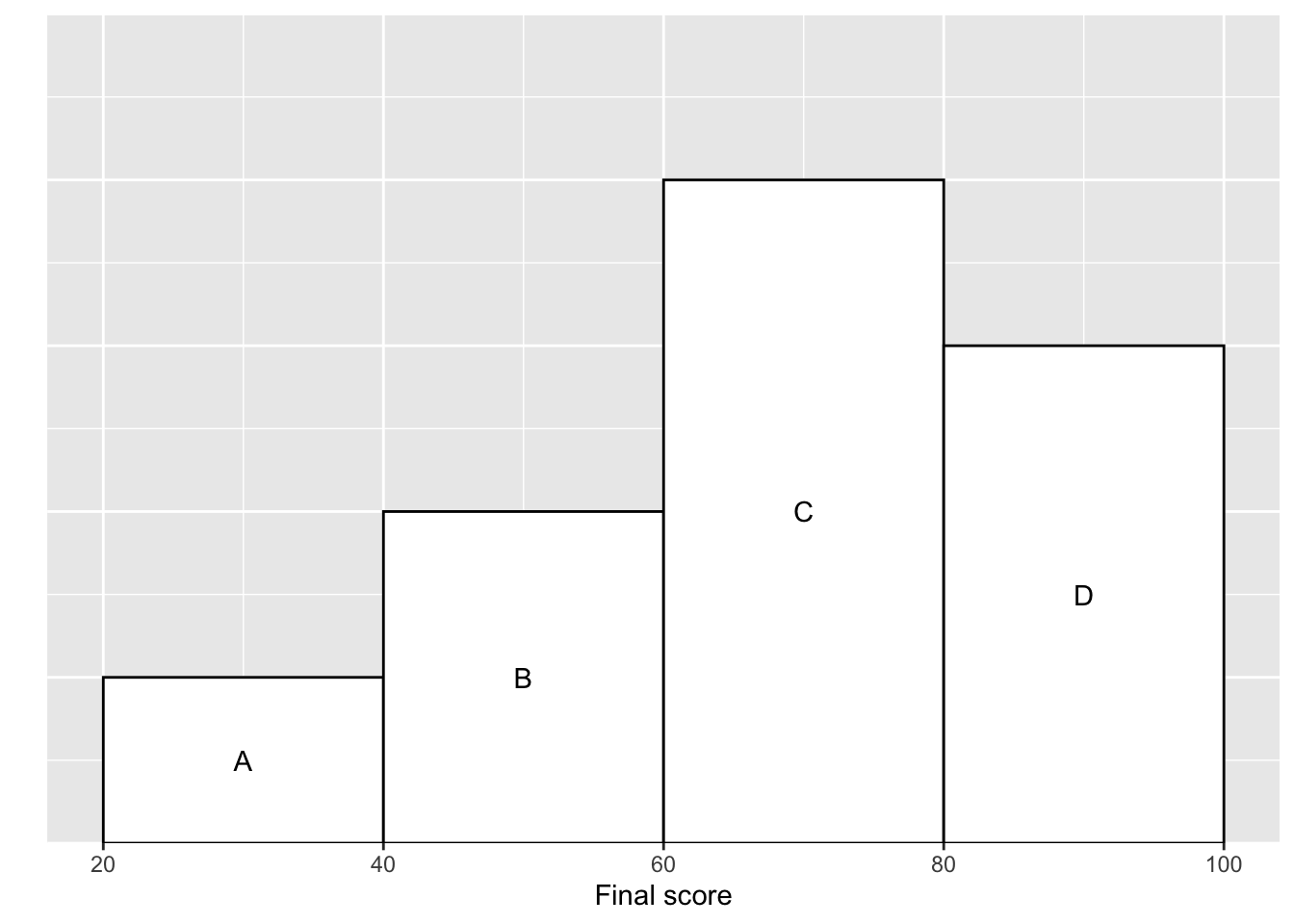
Który blok przedstawia osoby, które uzyskały wynik między 60 a 80?
Dziesięć procent studentów uzyskało wynik między 20 a 40. Jaka część studentów uzyskała wynik między 40 a 60? %
Jaki część studentów uzyskała wynik powyżej 60? %
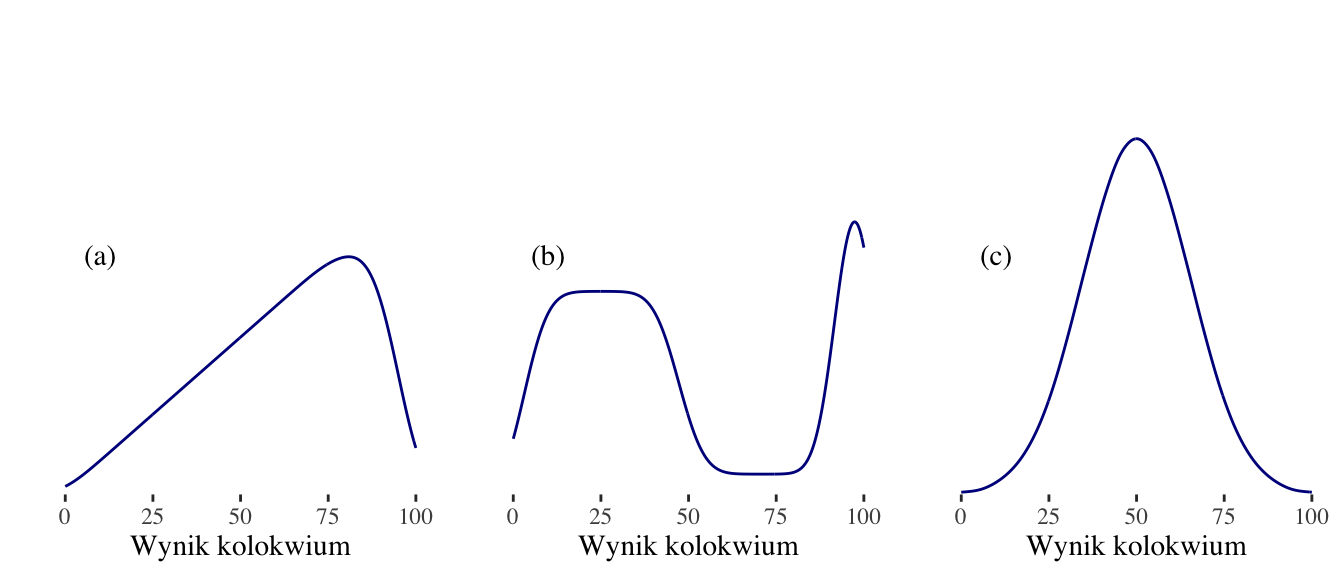
Zadanie 2.4 (Freedman, Pisani, and Purves 2007) Poniżej przedstawiono szkice histogramów (lub wykresy gęstości) wyników kolokwiów w trzech różnych grupach studenckich. Wyniki mieszczą się w przedziale od 0 do 100; próg zaliczenia wynosił 50. Czy w każdej grupie odsetek osób, które zdały, wynosił około 50%, znacznie powyżej 50% czy znacznie poniżej 50%?
Grupa (a):
Grupa (b):
Grupa (c):
Jedna z grup można uznać za złożoną z dwóch w dużej mierze odrębnych typów studentów: studentów, którzy wypadli raczej słabo i studentów, którzy wypadli bardzo dobrze. Która to była grupa?
Czy w grupie (b) było więcej osób z wynikami w przedziale 30-40 czy 90-100?
Literatura
Oficjalnie: służąca do „estymacji funkcji gęstości prawdopodobieństwa zmiennej ciągłej”↩︎