Rozdział 9 Regresja prosta
9.1 Linia odchylenia standardowego na wykresie rozrzutu
Przed wprowadzeniem regresji liniowej pomocne jest narysowanie linii odchylenia standardowego (linii SD) na wykresie rozrzutu (należy pamiętać, że linia SD nie jest linią regresji, która zostanie wprowadzona później).
Linia SD przechodzi przez punkt średnich (\(\bar{x}, \bar{y}\)), a jej nachylenie wynosi:
\[\text{nachylenie linii SD} = \pm \frac{s_y}{s_x} \tag{9.1} \]
Znak zależy od kierunku zależności między zmiennymi:
dodatnie nachylenie – jeśli współczynnik korelacji Pearsona jest dodatni (wyższe wartości X częściej odpowiadają wyższym wartościom Y,
ujemne nachylenie – jeśli współczynnik korelacji Pearsona jest ujemny.
Linia SD reprezentuje kierunek wspólnej zmienności zmiennych, odzwierciedlając ogólną orientację chmury punktów na wykresie punktowym w przypadku korelacji liniowej.
Rysunek 9.1: Wykres rozrzutu przedstawiający wzrost 1 078 ojców i ich dorosłych synów w Anglii około 1900 roku, wraz z linią SD (zaznaczoną na pomarańczowo).
Rysunek 9.2: Wykres rozrzutu z danymi o wzroście ojców i synów standaryzowanymi do z-scores. Linia SD na takim wykresie to przekątna y=x.
9.2 Średnie warunkowe na wykresie punktowym
Regresję liniową można traktować jako uproszczony sposób opisu tego, jak średnia warunkowa zmiennej \(Y\) zależy od wartości zmiennej (lub zmiennych) \(X\). Na rysunku 9.3 przedstawiono warunkowy średni wzrost synów w przedziałach wzrostu ojców. Średnie te stanowią intuicyjny punkt wyjścia do zrozumienia koncepcji regresji, ponieważ pokazują oczekiwaną wartość \(Y\) dla różnych zakresów \(X\). Jeśli średnie warunkowe tworzą w przybliżeniu linię prostą, wówczas model regresji liniowej może zapewnić rozsądny przybliżony opis związku między zmiennymi.
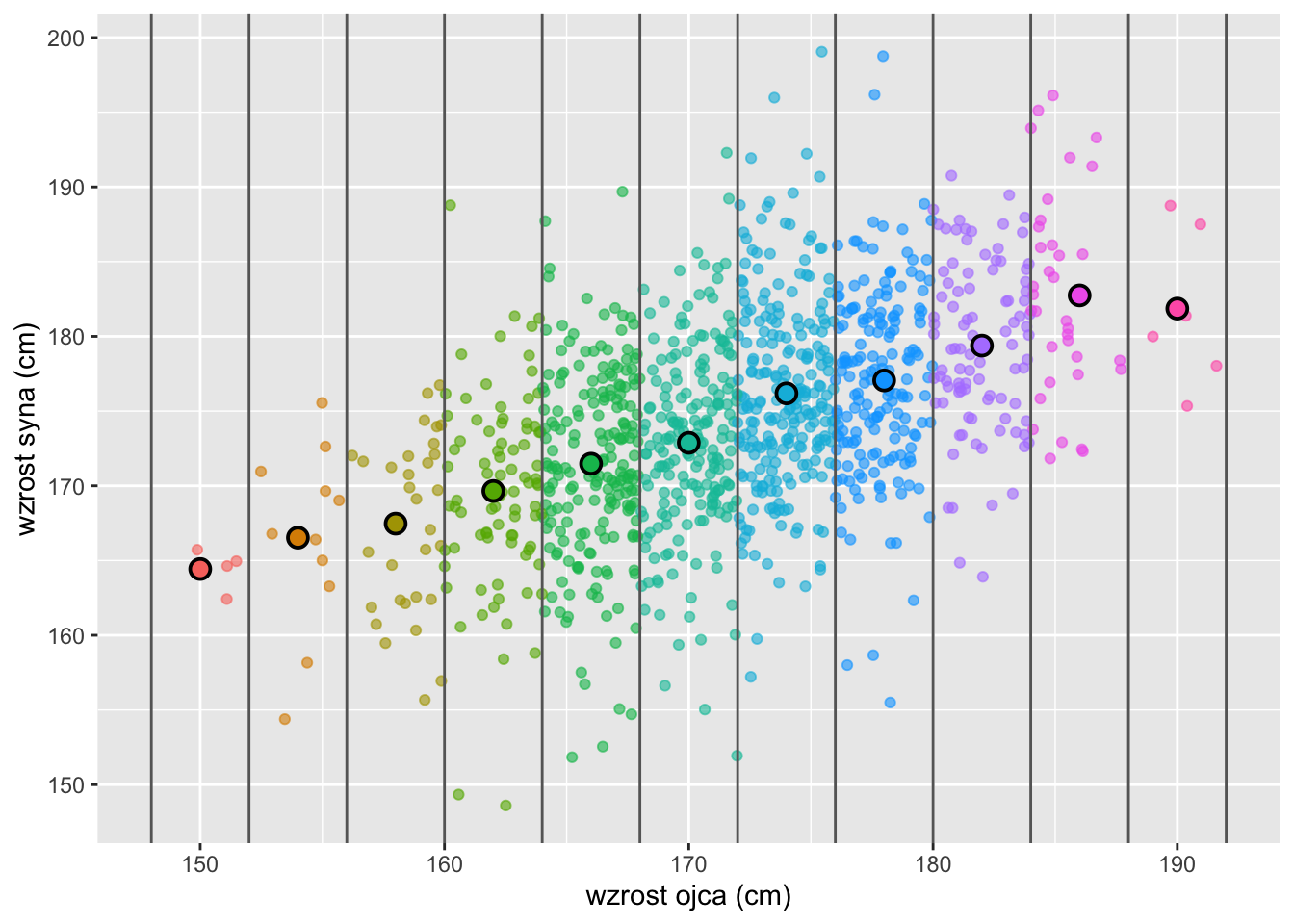
Rysunek 9.3: Wzrost ojców i synów przedstawiony na wykresie rozrzutu w postaci pojedynczych punktów, z wyróżnionymi wartościami średnimi wzrostu synów w grupach wyodrębnionych według przedziału wzrostu ojców.
9.3 Prosta regresja liniowa
9.3.1 Nazwy zmiennych
Prosta regresja liniowa to metoda statystyczna używana do opisania związku między dwiema zmiennymi ilościowymi:
Zmienna zależna (\(Y\)) to wynik, który chcemy przewidzieć lub wyjaśnić. Inne nazwy to zmienna objaśniana, zmienna odpowiedzi, zmienna przewidywana, zmienna wyjściowa lub zmienna celu.
Zmienna niezależna (\(X\)) to zmienna objaśniająca, wejściowa, predyktor lub regresor.
9.3.2 Linia regresji na wykresie rozrzutu
Linia regresji przedstawia przewidywane średnie wartości \(Y\) dla danych wartości \(X\) przy założeniu liniowej zależności. Intuicyjnie, linię regresji można rozumieć jako linię jak najlepiej pasującą do ogólnego trendu.
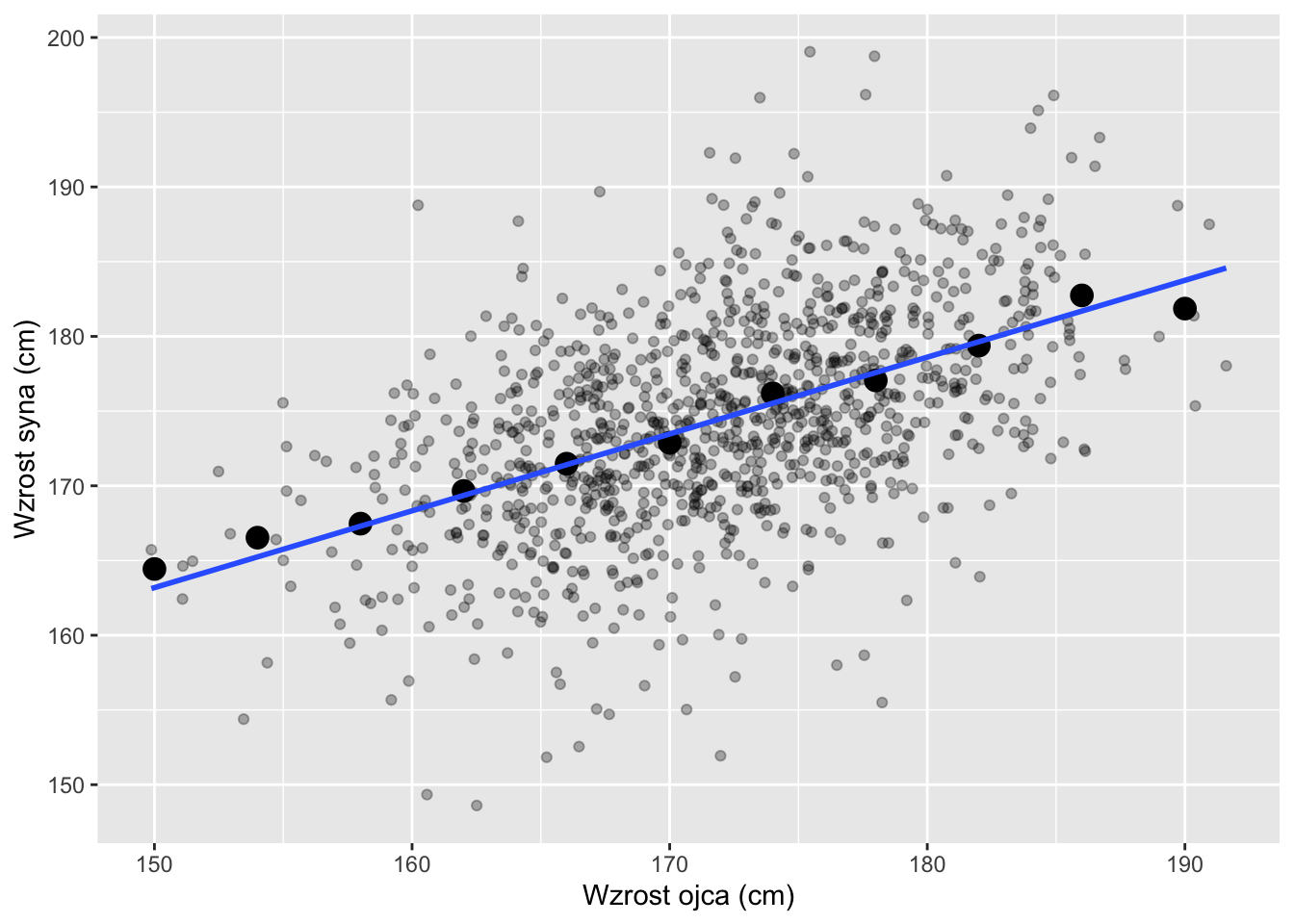
Rysunek 9.4: Wzrost ojców i synów, średnie grupowe i linia regresji
9.3.3 Wzór
Dopasowana linia regresji jest wyrażona jako:
\[\widehat{y_i} = \widehat{\beta}_0 + \widehat{\beta}_1 x_i, \tag{9.2}\]
gdzie:
\(x_i\) oznacza wartość zmiennej niezależnej \(X\),
\(\widehat{y_i}\) jest przewidywaną średnią \(Y\) przy \(X = x_i\),
\(\widehat{\beta}_0\) to wyraz wolny (punkt przecięcia linii regresji z osią Y),
\(\widehat{\beta}_1\) to nachylenie linii regresji.
Wyraz wolny jest przewidywaną średnią wartością \(y\) dla \(x_i=0\). Innymi słowy, jest to punkt, w którym dopasowana linia regresji przecina oś \(Y\).
Nachylenie informuje, o ile – przeciętnie rzecz biorąc – zmienia się przewidywana wartość \(Y\) przy jednostkowej zmianie \(X\). Dodatnie nachylenie oznacza, że \(Y\) ma tendencję do zwiększania się wraz ze wzrostem \(X\); ujemne nachylenie oznacza, że \(Y\) ma tendencję do zmniejszania się.
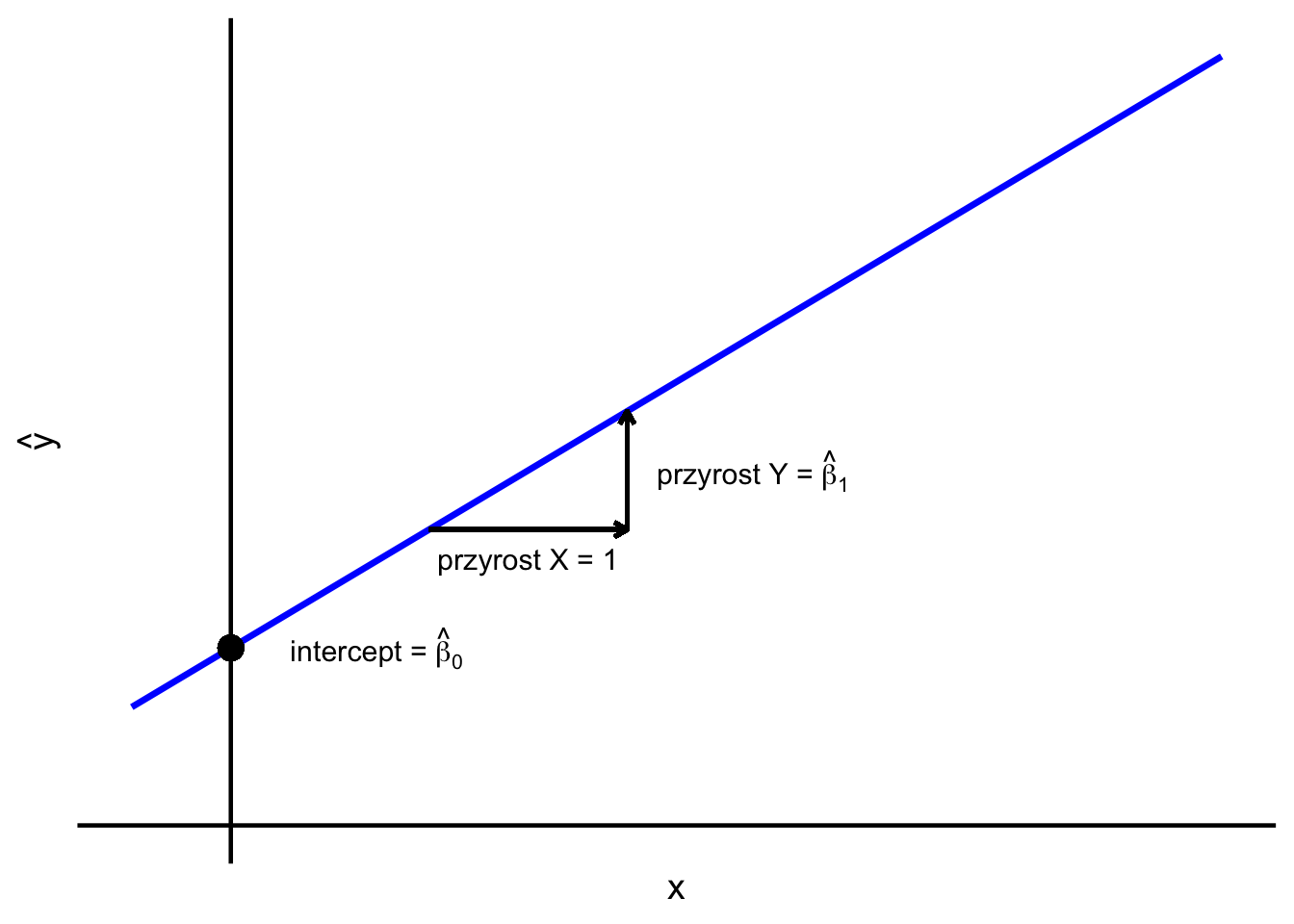
Rysunek 9.5: Linia regresji – wyraz wolny i nachylenie.
Istnieje wiele równoważnych wzorów na nachylenie dopasowanej linii regresji, ale najbardziej intuicyjne wyrażenie dla nachylenia łączy je z korelacją i odchyleniami standardowymi \(X\) i \(Y\):
\[\widehat{\beta}_1 = r_{xy} \frac{s_y}{s_x} \tag{9.3}\]
Dla każdego wzrostu odchylenia standardowego w \(X\), przewidywana wartość średniej \(Y\) zmienia się o \(r_{xy}\) razy odchylenie standardowe \(Y\). Wzór i jego praktyczne implikacje zilustrowano na rysunku 9.6.
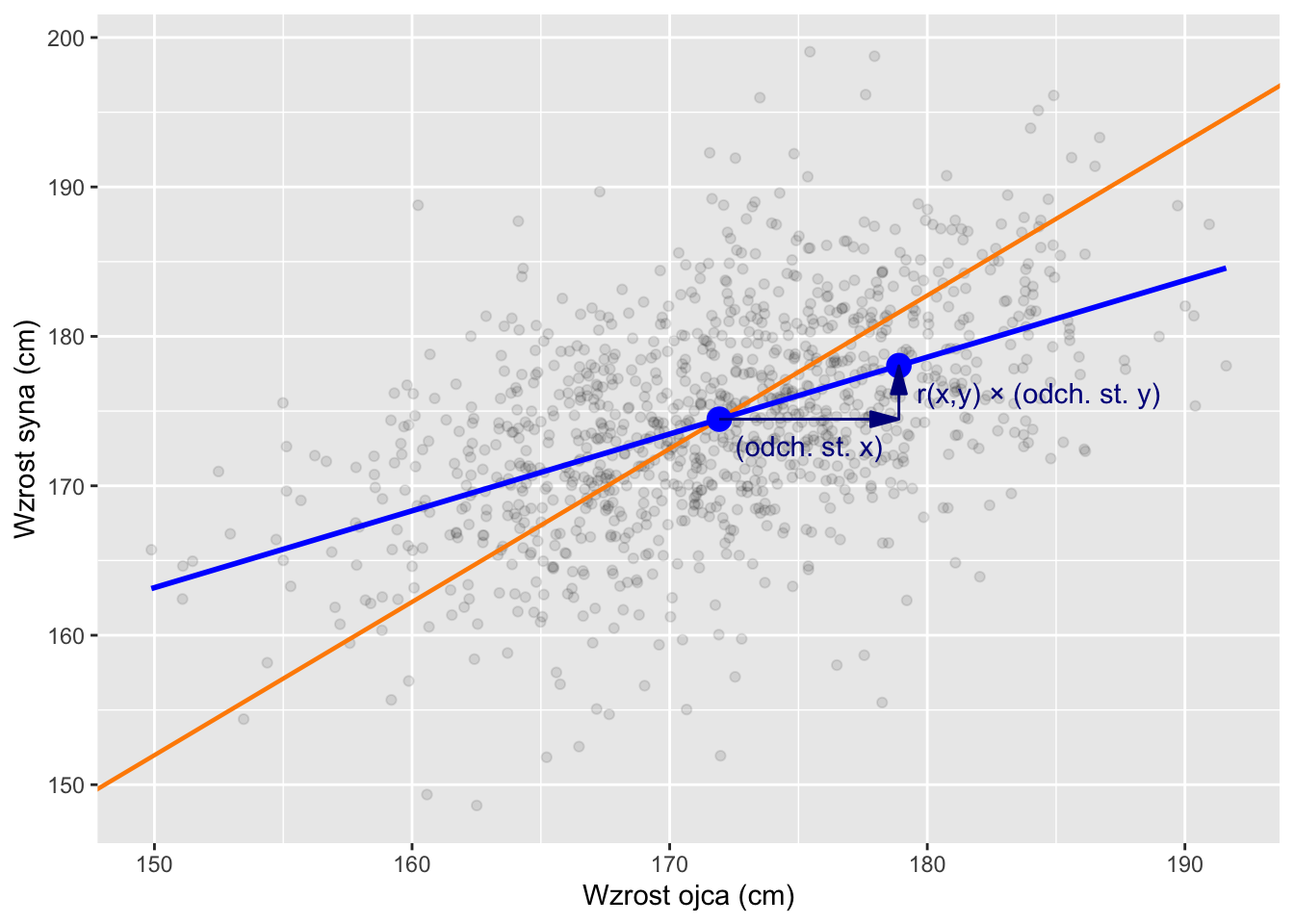
Rysunek 9.6: Nachylenie linii regresji odzwierciedla korelację między X i Y. Średnio wzrost X o jedno odchylenie standardowe odpowiada wzrostowi r razy odchylenie standardowe Y. Niebieska linia przedstawia linię regresji, ilustrującą przewidywany związek między X i Y. Pomarańczowa linia przedstawia linię SD. Niebieskie punkty oznaczają (1) punkt średnich (średnią X i Y) oraz (2) przewidywaną średnią wartość Y, gdy X jest o jedno odchylenie standardowe powyżej swojej średniej.
Punkt przecięcia dopasowanej linii regresji wyznacza się na podstawie wzoru:
\[\widehat{\beta}_0 = \bar{y} - \widehat{\beta}_1 \bar{x}. \tag{9.4}\]
Wzór (9.4) zapewnia, że linia regresji przechodzi przez punkt średnich \((\bar{x}, \bar{y})\), podobnie jak linia SD (patrz 9.6).
9.3.4 Reszty i najmniejsze kwadraty
Reszty (oznaczane jako \(e_i\) lub \(\widehat{\varepsilon}_i\)) to różnice między wartościami obserwowanymi a wartościami przewidywanymi:
\[e_i = y_i - \widehat{y}_i \tag{9.5}\]
Mierzą one pionową odległość każdego punktu danych od linii regresji. Analiza reszt pomaga ocenić dobroć dopasowania i wykryć wzorce, które mogą naruszać założenia modelu regresji.
Metoda najmniejszych kwadratów znajduje linię prostą, która minimalizuje sumę kwadratów reszt (SSR). Dla dowolnej linii zdefiniowanej przez \(\widehat{y}_i=b_0+b_1 x_i\), szukamy wartości \(b_0\) i \(b_1\), które minimalizują:
\[ \sum_{i=1}^{n}(y_i - \widehat{y}_i)^2 = \sum_{i=1}^{n}(y_i - b_0 - b_1 x_i)^2 \tag{9.6}\]
Linia, która osiąga to minimum, jest nazywana linią najmniejszych kwadratów. Jest to właśnie linia regresji. Podnoszenie reszt do kwadratu zapewnia, że dodatnie i ujemne odchylenia nie znoszą się, a większe odchylenia są karane bardziej niż mniejsze.
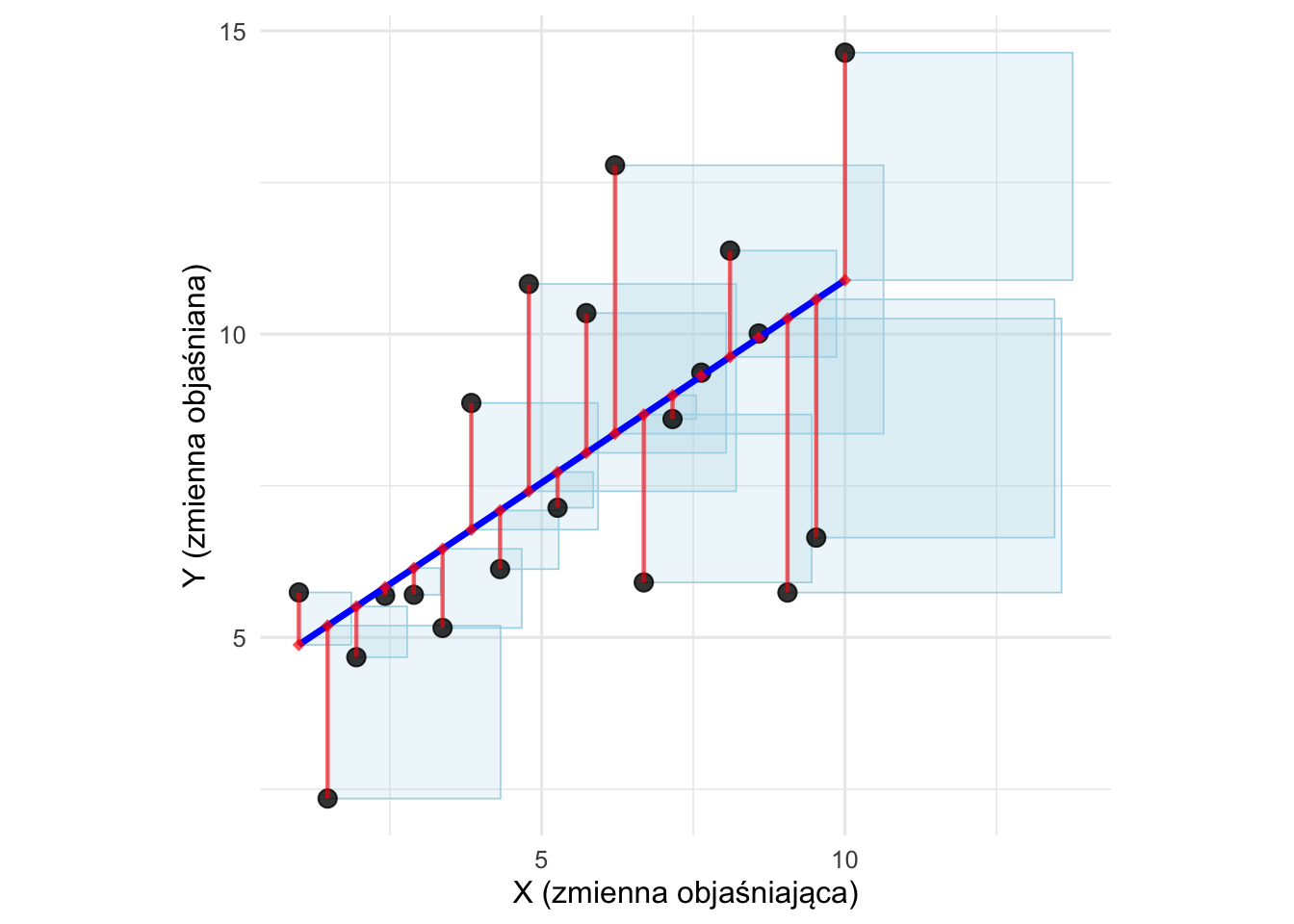
Rysunek 9.7: Wykres rozrzutu, linia regresji, reszty i kwadraty reszt. Linia regresji jest linią prostą minimalizującą całkowite pole kwadratów.
9.3.5 R-kwadrat
Współczynnik determinacji (\(R^2\), R-kwadrat) jest często opisywany jako frakcja (udział, część) zmienności w \(Y\), która może być wyjaśniona7 przez \(X\). Stwierdzenie to jest poprawne, ale tylko wtedy, gdy sprecyzujemy, że ta „zmienność” jest określana ilościowo za pomocą sumy kwadratów. Innymi słowy, \(R^2\) mierzy, jaka część całkowitej sumy kwadratów odchyleń w \(Y\) jest wyjaśniona przez model regresji.
\[R^2=1-\frac{\text{SS}_{res}}{\text{SS}_{tot}}, \tag{9.7}\]
gdzie:
- \(\text{SS}_{res}\) to suma kwadratów reszt modelu (ang. „residual sum of squares”):
\[\text{SS}_{res} = \sum_i{e_i^2} = \sum_i{(y_i-\widehat{y})^2} \tag{9.8}\]
- a \(\text{SS}_{tot}\) to „całkowita suma kwadratów” (ang. „total sum of squares”, suma kwadratów odchyleń od średniej, miara całkowitej zmienności):
\[\text{SS}_{tot} = \sum_i{(y_i-\bar{y})^2} \tag{9.9}\]
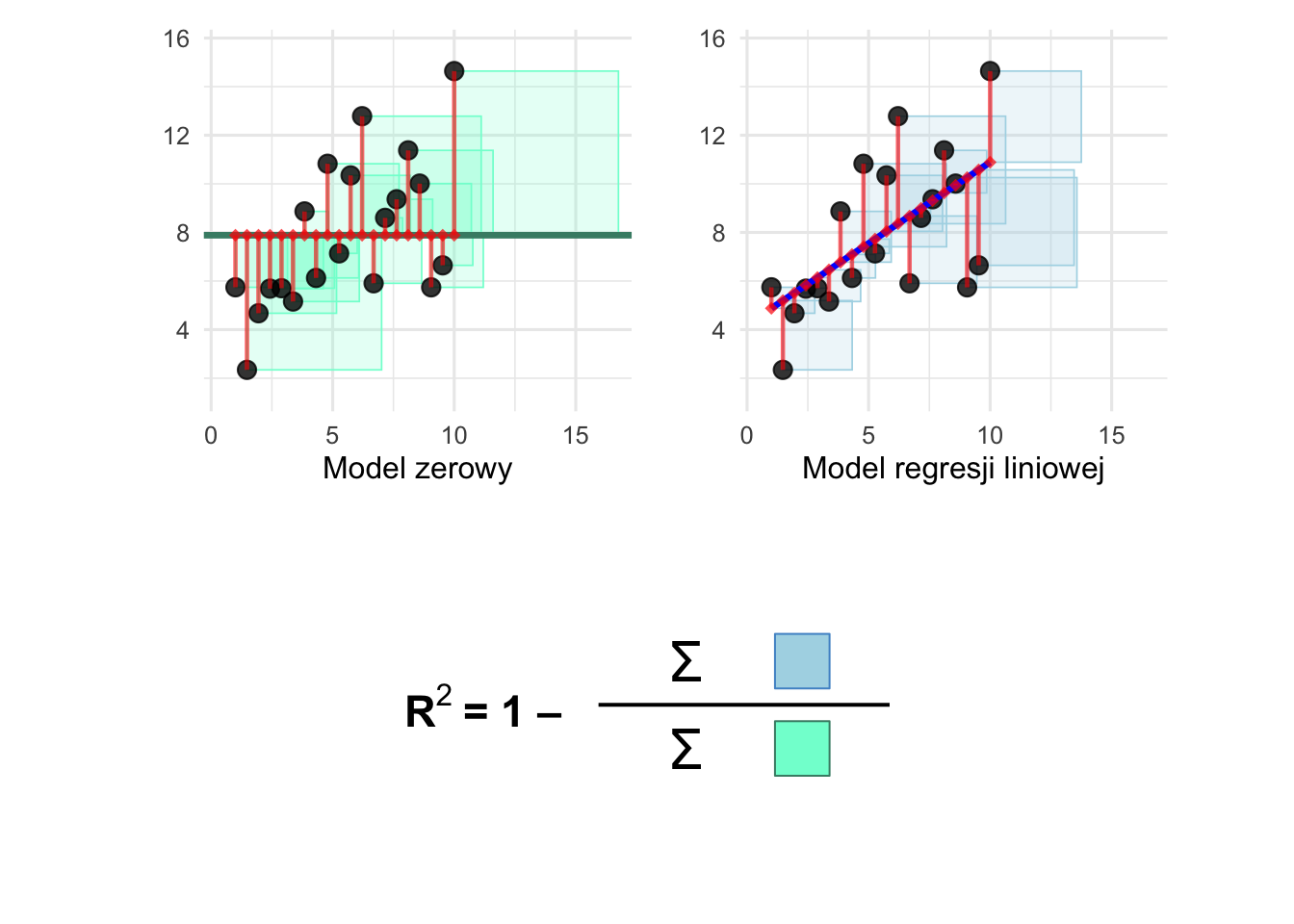
Rysunek 9.8: Graficzna ilustracja współczynnika determinacji R-kwadrat dla prostej regresji liniowej. Model „zerowy” to model zwracający średnią wartość y niezależnie od zadanego x.
Dla prostej regresji liniowej R-kwadrat jest równoważny podniesionemu do kwadratu współczynnikowi korelacji Pearsona:
\[R^2 = r_{xy}^2 \tag{9.10}\]
9.4 Wykorzystanie i interpretacja regresji
9.4.1 Cel modeli regresji
Regresja liniowa i podobne modele statystyczne są wykorzystywane do:
opisywania związku między X i Y w zbiorze danych (i szacowania parametrów tego związku w procesie generującym dane),
przewidywania zmiennej zależnej na podstawie wartości zmiennych objaśniających \(X\),
badania potencjalnych struktur przyczynowych między \(X\) a \(Y\), również w celu oceny możliwości interwencji.
Regresja liniowa jest stosunkowo prostym narzędziem do opisywania związków w danych. Dopasowując model liniowy, możemy określić ilościowo, w jaki sposób zmienna objaśniająca jest powiązana ze zmienną objaśnianą, podsumować ogólną strukturę danych, zbadać zmienność, która pozostaje niewyjaśniona.
Predykcja zazwyczaj opiera się na założeniu, że proces generujący nowe obserwacje jest podobny do tego, który wygenerował dostępny zbiór danych. Stanowi ona uporządkowany sposób estymacji nieobserwowanych wartości na podstawie zaobserwowanych prawidłowości. Predykcja oparta na modelach regresyjnych znajduje zastosowanie m.in. w prognozowaniu, uzupełnianiu braków danych (imputacji), interpolacji i wygładzaniu, wykrywaniu obserwacji odstających oraz w wielu innych sytuacjach.
Regresja nie stanowi dowodu przyczynowości przyczynowości (por. korelacja nie implikuje przyczynowości (8.3), lecz może wskazywać na zależności, które przy spełnieniu dodatkowych założeń mogą być interpretowane przyczynowo. Wnioskowanie takie wymaga zwykle eksperymentów (np. randomizowanych badań kontrolowanych) lub silnego uzasadnienia opartego na wiedzy dziedzinowej. W badaniach obserwacyjnych (1.1) regresja służy głównie do opisu zależności statystycznych oraz kontroli obserwowalnych czynników zakłócających (ang. confounders), a uzyskane wyniki należy interpretować ostrożnie i traktować jako punkt wyjścia do dalszych analiz, a nie jako bezpośredni dowód przyczynowości.
9.4.2 Interpretacja dopasowanego modelu
W prostej regresji liniowej trzy liczby opisują strukturę danych:
wyraz wolny (punkt przecięcia, \(\widehat{\beta}_0\)),
nachylenie (\(\widehat{\beta}_1\)),
odchylenie standardowe reszt (oznaczane jako \(s_{e}\), \(\widehat{\sigma}_\varepsilon\) lub \(\text{RSD}\)).
Wyraz wolny (\(\widehat{\beta}_0\)) przedstawia oszacowanie średniej wartości \(Y\), gdy \(X=0\). W wielu przypadkach wartość ta jest czysto teoretyczna – zwłaszcza gdy 0 leży poza zakresem obserwowanych \(X\)-ów, a w ogóle nawet poza dopuszczalnym zakresem wartości. Jednak we wszystkich przypadkach punkt przecięcia pozostaje niezbędnym składnikiem równania regresji: jego uwzględnienie zapewnia, że dopasowana linia najlepiej pasuje do danych.
Współczynnik nachylenia linii regresji (\(\widehat{\beta}_1\)) przedstawia oszacowanie średniej różnicy w wartościach zmiennej objaśnianej (\(Y\)) towarzyszącej jednostkowej różnicy w wartościach zmiennej \(X\). Załóżmy, że mamy do czynienia z dwiem grupami obserwacji: jedną, w której \(X=x\), i drugą, w której \(X=x+1\). Według modelu prostej regresji liniowej różnica między średnią wartością \(Y\) w obu tych grupach to \(\widehat{\beta}_1\). Warto zaznaczyć jeszcze raz, że opisujemy to zależność statystyczną, a nie przyczynowo-skutkową. Nie twierdzimy, że przyrost zmiennej \(X\) powoduje zmianę Y. Dopasowana linia regresji podsumowuje sposób, w jaki dwie wartości wspólnie się zmieniają, bez implikowania żadnego mechanizmu przyczynowego.
Współczynnik nachylenia zależy od zastosowanych jednostek. Zmiana jednostki pomiaru zmiennej \(X\) proporcjonalnie zmienia wartość liczbową \(\widehat{\beta}_1\). Na przykład po przeliczeniu wzrostu (\(X\)) z centymetrów na metry współczynik nachylenia zmieni się stukrotnie. Podobnie, gdy przeliczymy wynagrodzenie ze złotych na dolary, współczynnik nachylenia będzie odpowiednio przeskalowany zgodnie z kursem walutowym. W takich sytuacjach wartość liczbowa się zmienia, ale oczywiście nie zmienia się znaczenie i interpretacja współczynnika.
Odchylenie standardowe reszt (inaczej: resztkowe odchylenie standardowe, po angielsku residual standard deviation, w wydrukach R jest to residual standard error) wyznacza się, w przypadku prostej regresji liniowej, zgodnie z następującym wzorem:
\[ \text{RSD} = \sqrt{\frac{1}{n-2}\sum_{i=1}^n\left(y_i-\widehat{y}\right)^2} \tag{9.11}\]
Resztkowe odchylenie standardowe (RSD) mierzy typową wielkość błędów predykcji, wyrażoną w jednostkach zmiennej zależnej. Innymi słowy, określa typowy stopień odchylenia obserwacji od linii regresji. Mniejsze RSD oznacza lepsze dopasowanie modelu do danych, natomiast większe RSD wskazuje, że przewidywania modelu są bardziej rozproszone i mniej precyzyjne.
Rysunek 9.9 ilustruje praktyczne znaczenie RSD.
.](_main_files/figure-html/rsdrule-1.png)
Rysunek 9.9: Ilustracja reguły 68-95 dla odchylenia standardowego reszt (RSD). Zobacz także wersję interaktywną.
Resztkowe odchylenie standardowe jest związane z R-kwadrat:
\[ RSD = \left(s_y \sqrt{1 - R^2} \right) \sqrt{\frac{n-1}{n-2}} \tag{9.12}\]
Przydatne może być następujące przybliżenie:
\[ RSD \approx s_y \sqrt{1 - R^2} \tag{9.13}\]
Przykład
Poniżej znajduje się wydruk wyników dopasowania modelu regresji z programu R. Dane przedstawiono na rysunku 9.10. Model opisuje relację między wzrostem (\(X\)) a rozpiętością prawej dłoni (\(Y\)) z wykorzystaniem danych pochodzących od 381 studentów.
Rysunek 9.10: Rozpiętość dłoni a wzrost - wykres rozrzutu i linia regresji. Dane zebrane od 381 studentów.
##
## Call:
## lm(formula = right_hand_span ~ height, data = students)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.9125 -1.0503 0.0765 1.0521 4.4655
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -3.890818 1.532902 -2.538 0.0115 *
## height 0.137796 0.008718 15.807 <0.0000000000000002 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.579 on 379 degrees of freedom
## (2 observations deleted due to missingness)
## Multiple R-squared: 0.3973, Adjusted R-squared: 0.3957
## F-statistic: 249.8 on 1 and 379 DF, p-value: < 0.00000000000000022Wyraz wolny \(\widehat{\beta}_0\) to -3,891, zaś nachylenie \(\widehat{\beta}_1\) wynosi 0,138. Odchylenie standardowe reszt wynosi 1,579. R-kwadrat wynosi 0,397.
Technicznie rzecz ujmując, wyraz wolny to przewidywana przez model rozpiętość prawej dłoni dla osóby o wzroście równym 0 cm. Oczywiście taka wartość nie ma sensownej interpretacji. W tym przypadku wyraz wolny (-3,891) to po prostu punikt przecięcia linii regresji z osią y.
Współczynnik nachylenia natomiast można jednoznacznie zinterpretować. Wskazuje on, że zgodnie z modelem średnia rozpiętość dłoni zwiększa się o 1,38 mm dla każdego kolejnego centymetra wzrostu.
Zaobserwowane wartości \(Y\) odchylają się od linii regresji, miarą stopnia tych odchyleń jest odchylenie standardowe reszt (wynoszące 1,579 cm). Model wyjaśnia 39,7% zmienności \(Y\).
9.4.3 Predykcja
Przewidując wartości zmiennej \(Y\) dla nowych obserwacji na podstawie znanych wartości \(X\), opieramy się na założeniu, że proces generujący dane może być przybliżony przez zależność liniową.
Do sprawdzenia tego założenia w praktyce może posłużyć wykres rozrzutu \(Y\) względem \(X\). Jeżeli na wykresie chmura tworzona na wykresie ma w kształt przypominający elipsę, można uznać, że liniowe przybliżenie jest uzasadnione.
Regresja liniowa umożliwia predykcję punktową, czyli przewidywanie średniej wartości \(Y\) dla danego \(X\). Punktowymi przewidywaniami są wartości \(\widehat{y}\) leżące na dopasowanej linii regresji.
Aby uwzględnić niepewność, możemy skonstruować przedziały ufności. Przedział ufności, dla danej wartości \(X\), podaje zakres, w którym prawdopodobnie znajduje się warunkowa średnia \(Y\). Nawet jeśli założymy, że podstawowa zależność jest liniowa, nie wiemy, czy na ile dopasowana linia odbiega od prawdziwej linii właściwej dla procesu generującego dane. Przedział ufności uwzględnia tę niepewność.
Możemy być również zainteresowani przedziałami predykcji. Przedział predykcji to przedział, który odzwierciedla prawdopodobny zakres pojedynczej nowej obserwacji \(Y\) dla ustalonego \(X\). Jest on szerszy niż przedział ufności (przedział pokazujący możliwy zakres warunkowej średniej), ponieważ uwzględnia zarówno niepewność w szacowaniu średniej, jak i naturalną zmienność poszczególnych obserwacji wokół warunkowej średniej.
Dokładne wzory na przedziały ufności i predykcji są podane w kursie 2 semestru statystyki statystyka 2.
W kontekście predykcji z wykorzystaniem regresji liniowej, należy pamiętać o różnicy między interpolacją a ekstrapolacją. Interpolacja odnosi się do przewidywania \(Y\) dla wartości \(X\), które leżą wewnątrz zakresu obserwowanych danych. W tym przypadku model jest wspierany przez dane, a przybliżenie liniowe jest zwykle rozsądne. Ekstrapolacja nastomiast obejmuje przewidywanie \(Y\) dla wartości \(X\), które znajdują się poza zakresem próbki. W tym przypadku model musi całkowicie polegać na założonej formie funkcyjnej – w tym przypadku linii prostej – choć brak danych, które mogłyby potwierdzić to założenie. W rezultacie ekstrapolowane przewidywania mogą być wysoce niewiarygodne, zaś zarówno przedziały ufności i predykcji mają tendencję do zaniżania rzeczywistej niepewności.
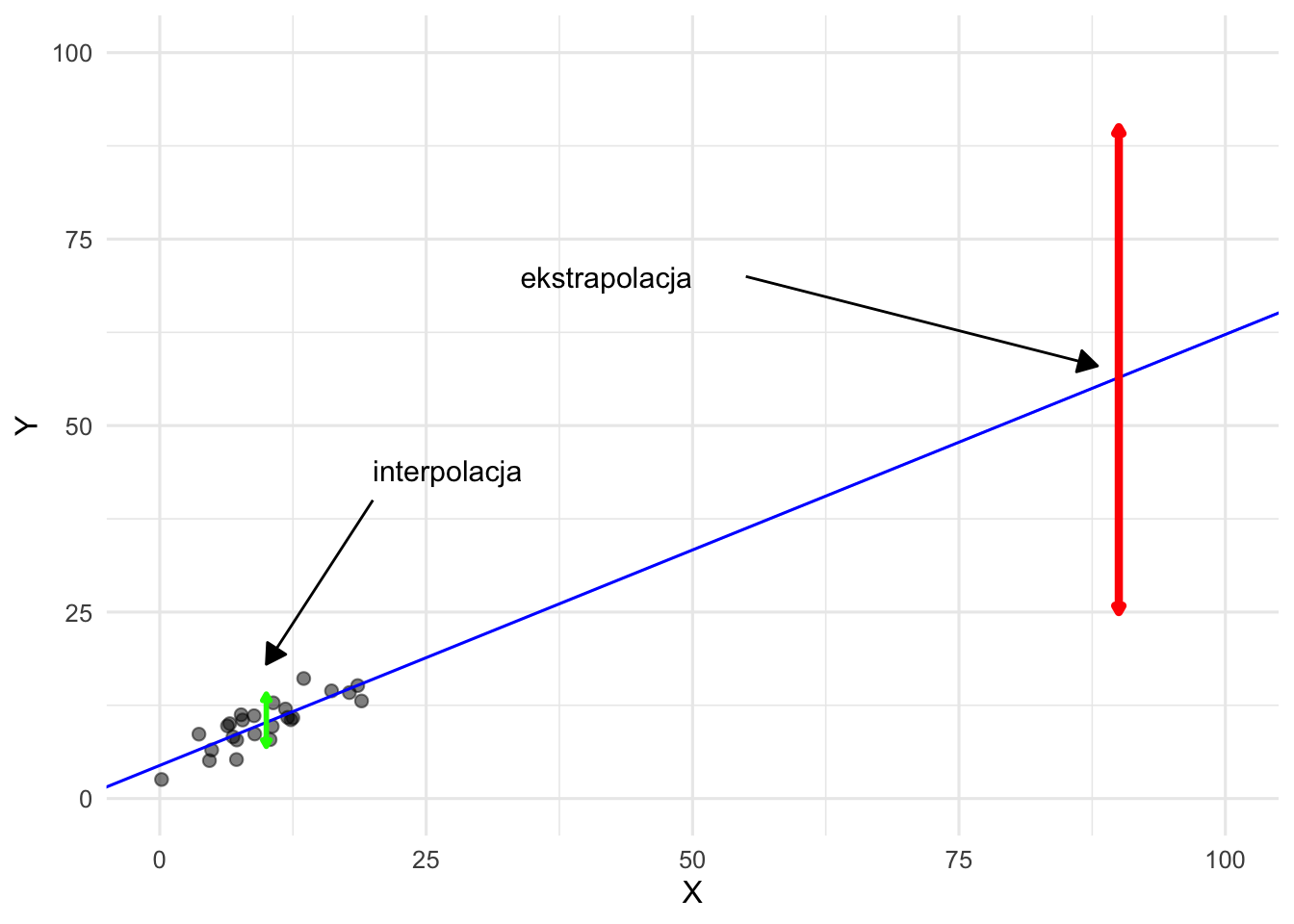
Rysunek 9.11: Gdy używamy modelu regresji liniowej do predykcji, interpolacja jest w dużo mniejszym stopniu obarczona niepewnością niż ekstrapolacja.
9.5 Regresja do średniej
Określenie regresja wywodzi się z XIX-wiecznych badań Francisa Galtona. Zauważył on, że wzrost synów miał tendencję do powrotu („regresji”) w kierunku średniej populacyjnej. Bardzo wysocy ojcowie zwykle mieli wysokich synów, jednak nie tak wysokich jak oni sami; bardzo niscy ojcowie mieli synów niskich, lecz bliższych średniej. Galton najpierw sądził, że zjawisko, które odkrył, nazwane regresją do średniej, stanowi coś wyjątkowego. Później wykazano, że jest to po prostu matematyczna konsekwencja niedoskonałej korelacji.
Rysunek 9.12 ilustruje tę koncepcję przy użyciu danych Galtona dotyczących wzrostu ojców i synów. Czarne punkty przedstawiają średnie grupowe, niebieska linia to linia regresji, a pomarańczowa linia pokazuje linię SD (idealna korelacja). Zauważ, że linia regresji jest mniej nachylona niż linia SD, co stanowi przejaw „powrotu do średniej”.
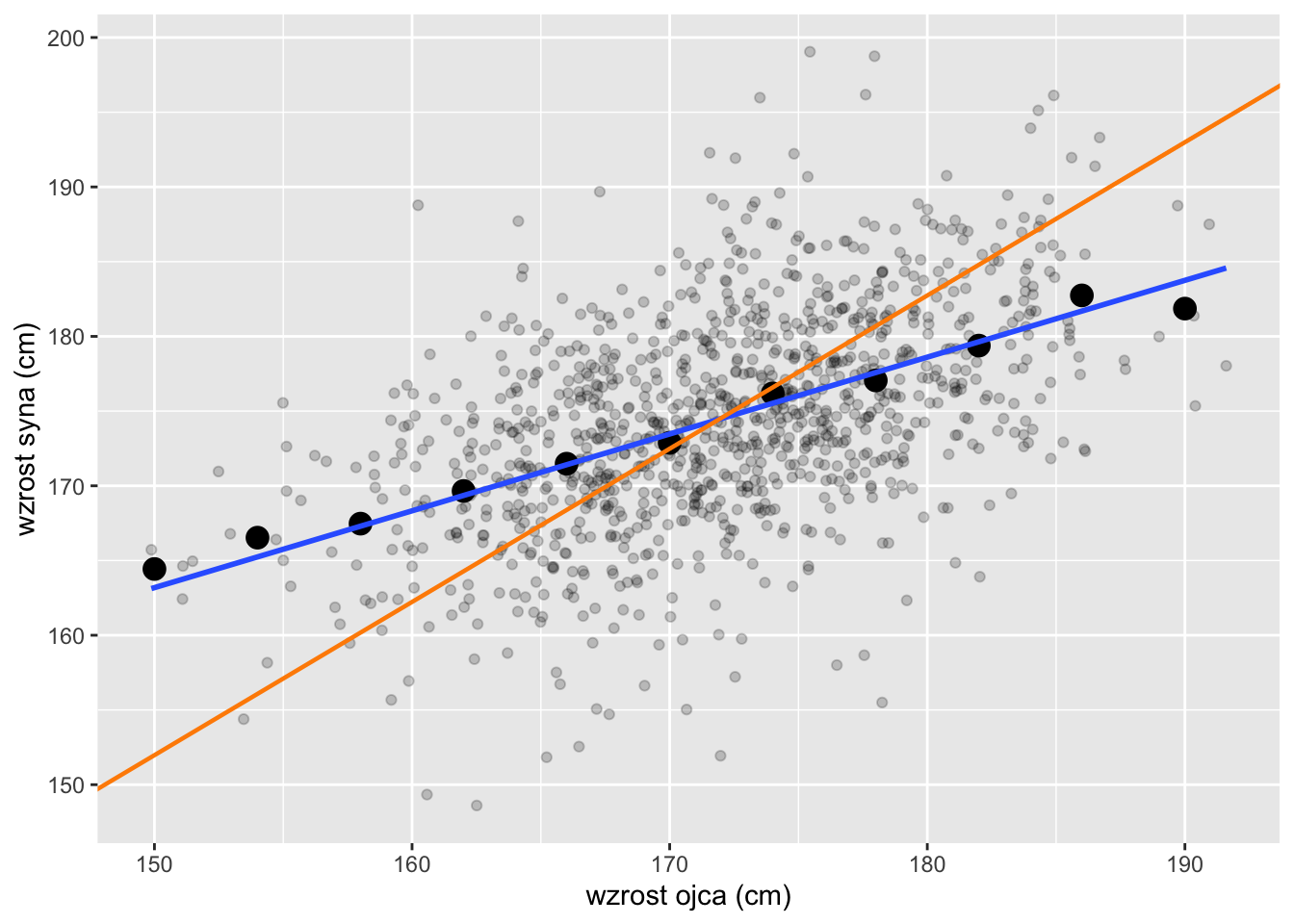
Rysunek 9.12: Wzrost ojców i synów, średnie grupowe, linia regresji (niebieska) i linia SD (pomarańczowa)
Regresja do średniej występuje w wielu innych rzeczywistych kontekstach:
Powtórzone testowanie: Uczniowie, którzy uzyskali bardzo wysokie lub niskie wyniki w teście, często uzyskują wyniki bliższe średniej w powtórzonym teście. Dzieje się tak, ponieważ część skrajnego wyniku jest efektem „szczęścia” – czynników losowych, które raczej się nie powtórzą.
Kojarzenie asortatywne z niedoskonałą korelacją: Bardzo inteligentne kobiety są zwykle żonami mężczyzn, którzy są inteligentni, ale zazwyczaj mniej inteligentni niż one same. Odzwierciedla to fakt, że inteligencja (mierzona na przykład przez IQ) między partnerami jest skorelowana, ale współczynnik korelacji nie wynosi 1.
Pomiary medyczne: Pacjenci ze skrajnie wysokim ciśnieniem krwi podczas jednej wizyty często wykazują niższe odczyty podczas następnej wizyty, nawet bez leczenia. Jest to częściowo spowodowane zmiennością pomiarów i tymczasowymi warunkami, a nie poprawą stanu pacjentów.
9.6 Regresja vs korelacja
Prosta regresja liniowa jest ściśle związana z korelacją Pearsona:
Współczynnik nachylenia i współczynnik korelacji. Nachylenie linii regresji zależy bezpośrednio od korelacji między \(X\) i \(Y\) – patrz równanie (9.3). Gdy obie zmienne są znormalizowane do z-scores, współczynnik nachylenia jest równe współczynnikowi korelacji.
Znak współczynnika nachylenia regresji jest taki sam jak znak współczynnika korelacji.
Współczynnik determinacji. Wartość \(R^2\) w prostej regresji liniowej jest równa podniesionemu do kwadratu współczynnikowi korelacji Pearsona (patrz (9.10)).
Korelacja i regresja są pojęciami powiązanymi, ale różnią się w kluczowy sposób:
Korelacja jest symetryczna – zamiana \(X\) i \(Y\) nie zmienia korelacji; natomiast regresja jest kierunkowa modeluje się jedną zmienną jako zależną od drugiej: zamiana \(X\) i \(Y\) zmienia wartość współczynnika nachylenia i punkt przecięcia.
Współczynnik korelacji jest bezwymiarowy i zawsze mieści się w przedziale od -1 do 1. W przypadku regresji jednostki mają znaczenie: nachylenie zależy od jednostek pomiaru \(X\) i \(Y\).
Wreszcie, korelacja po prostu mierzy siłę i kierunek związku liniowego, podczas gdy regresja wykracza poza opis: dostarcza wzoru, który można wykorzystać do przewidywania i wyjaśniania.
9.7 Transformacja zmiennych
Czasami związek między dwiema zmiennymi nie jest liniowy, ale transformacja zmiennych może przekształcić dane w sposób, który umożliwi wykorzystanie modelu liniowego.
Najpopularniejszym przekształceniem jest logarytm naturalny8: \(x^* = \ln(x)\). Przekształcenie to jest szczególnie przydatne, gdy:
zależność między zmiennymi jest monotoniczna, ale krzywoliniowa i zbliżona do prawa potęgowego, przykładem może być zależność między wzrostem a masą ciała zwierząt;
wartości obejmują kilka rzędów wielkości, np. dochody od setek do milionów; .
związek dobrze opisany jest przez zmiany względne, oparte na procentach, np. zmiany cen;
następuje gwałtowny wzrost wartości zmiennej; przykładem może być wzrost populacji lub rozprzestrzenianie się wirusa;
zmienność wzrasta wraz z poziomem zmiennej, jak w przypadku danych dotyczących sprzedaży, gdzie przychody dla dużych sklepów są bardziej zmienne niż dla małych.
Inne przydatne transformacje obejmują pierwiastek kwadratowy (\(x^* = \sqrt{x}\)) i odwrotność (\(x^* = 1/x\)). Transformacje mogą pomóc w „prostowaniu zakrzywionych związków” lub stabilizowaniu zmienności.
9.7.1 Przewidywanie przy użyciu modelu liniowego log-log
W modelu regresji, który nazwiemy tutaj „log-log”, zarówno X, jak i Y są przed dopasowaniem modelu zlogarytmowane. Dopasowane równanie ma postać:
\[\widehat{\ln(y_i)} = \widehat{\beta}_0 + \widehat{\beta}_1\ln(x_i) \tag{9.14}\]
Aby wyznaczyć prognozę \(\widehat{y_p}\) dla nowej obserwacji \(X=x_p\), należy najpierw obliczyć przewidywaną wartość \(\ln(y)\) przy użyciu modelu, a następnie przekształcić ją z powrotem do oryginalnej skali poprzez zastosowanie funkcji wykładniczej \(\exp{a}=\text{e}^a\):
\[\widehat{y_p} = \exp(\widehat{\beta}_0 + \widehat{\beta}_1\ln(x_p)) \tag{9.15}\]
Ten ostatni krok jest ważny, ponieważ model regresji jest w skali logarytmicznej, ale prognozy są zwykle potrzebne w oryginalnych jednostkach (takich jak kilogramy lub metry).
W modelu log-log współczynnik nachylenia (\(\widehat{\beta}_1\)) ma następującą interpretację: odzwierciedla on przybliżoną procentową zmianę średniej Y dla 1-procentowej różnicy w X.
9.8 Ograniczenia regresji liniowej
Chociaż regresja liniowa jest powszechnie stosowana, ma ona kilka istotnych ograniczeń.
Zakłada, że związek między X i Y da się opisać linią prostą (liniowość), że zmienność Y jest podobna dla wszystkich wartości X (homoskedastyczność) i że nie ma ekstremalnych wartości odstających, które zdominowałyby wyniki. Gdy te założenia nie są spełnione, przewidywania i interpretacje modelu mogą być mylące.
Regresja liniowa wychwytuje tylko jeden rodzaj relacji – zależność liniową – i nie może wykryć bardziej złożonych wzorców, chyba że model zostanie rozszerzony lub poprawiony.
Wreszcie, regresja opisuje związek, a nie przyczynowość. Nawet silna zależność liniowa nie dowodzi, że zmiany w X powodują zmiany w Y.
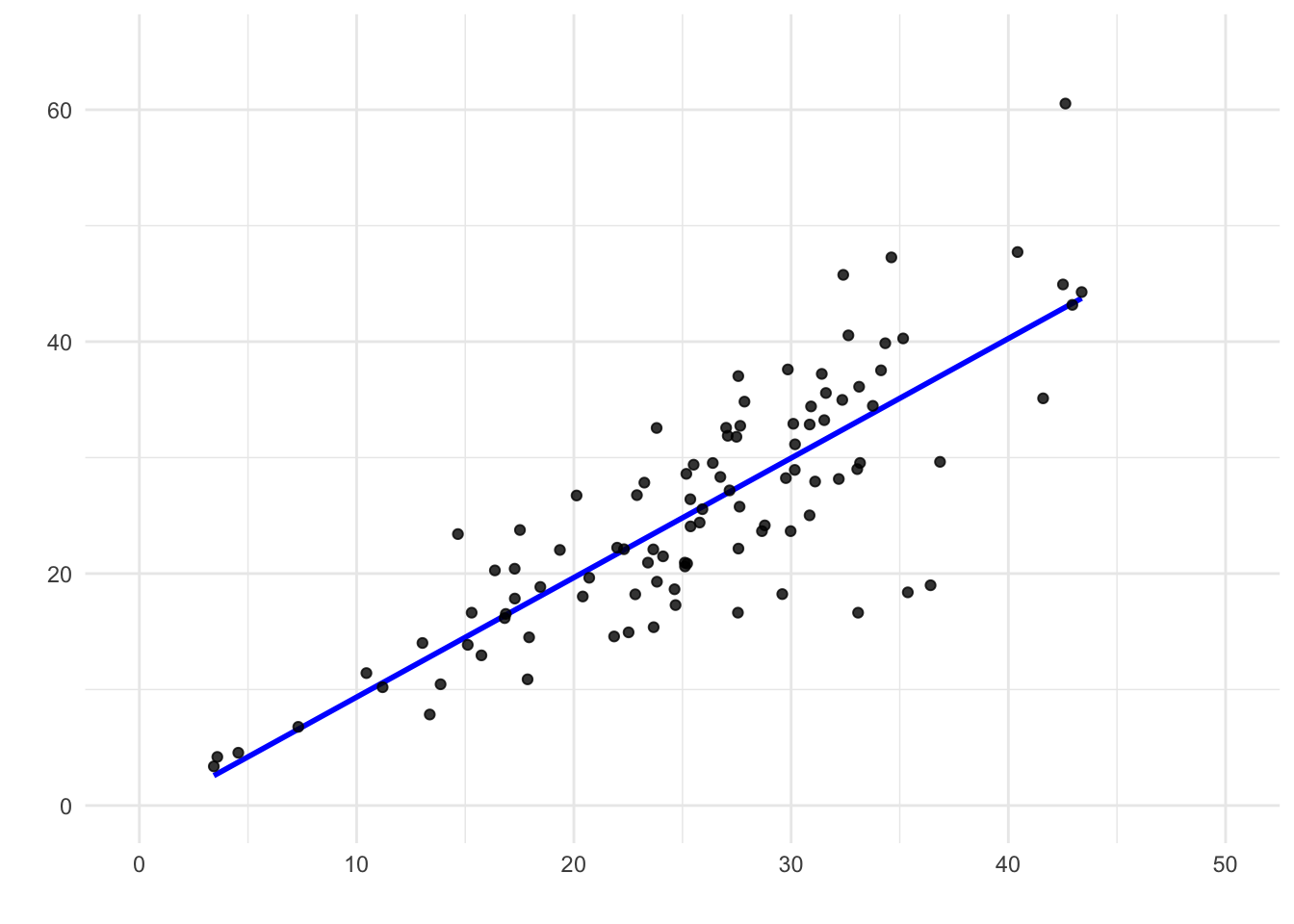
Rysunek 9.13: Wykres rozrzutu pokazujący heteroskedastyczność. Chociaż linia prosta dobrze pasuje do trendu centralnego, zmienność reszt zmienia się na różnych poziomach X.
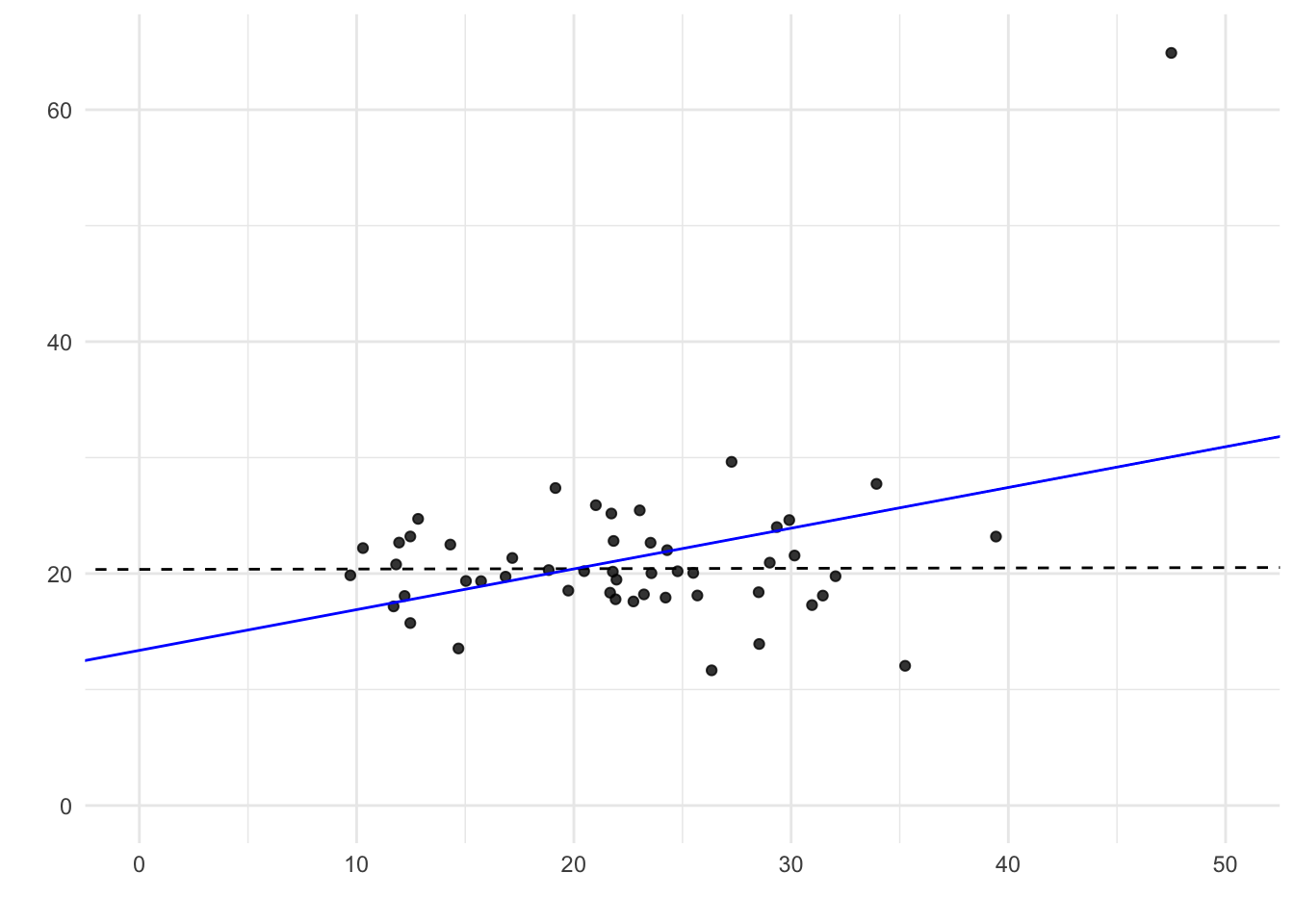
Rysunek 9.14: Wartości odstające mogą zniekształcać wyniki regresji. Pojedyncza wartość odstająca może zmienić dopasowaną linię i stworzyć fałszywe nachylenie. Niebieska linia jest dopasowana przy użyciu wszystkich obserwacji, podczas gdy linia przerywana jest dopasowana po usunięciu wartości odstającej w prawym górnym rogu.
9.9 Linki
Wykres rozrzutu i linia regresji – aplikacja webowa: https://istats.shinyapps.io/ExploreLinReg/
Zasada najmniejszych kwadratów — wizualizacja: https://college.cengage.com/nextbook/statistics/utts_13540/student/html/simulation3_1.html
Wykres rozrzutu, zasada najmniejszych kwadratów i linia regresji: https://bankonomia.nazwa.pl/regressionclick/
R-kwadrat – wizualizacja: https://college.cengage.com/nextbook/statistics/utts_13540/student/html/simulation3_4.html
Wpływ wartości odstających na model regresji: https://college.cengage.com/nextbook/statistics/utts_13540/student/html/simulation3_5.html
Prosta regresja – kolejna wizualizacja: https://observablehq.com/@yizhe-ang/interactive-visualization-of-linear-regression.
Regresja do średniej – wprowadzenie z przykładami: https://fs.blog/regression-to-the-mean/
Istnieją dwie linie regresji: https://bankonomia.nazwa.pl/tworeglines/
9.10 Pytania
9.10.1 Pytania do dyskusji
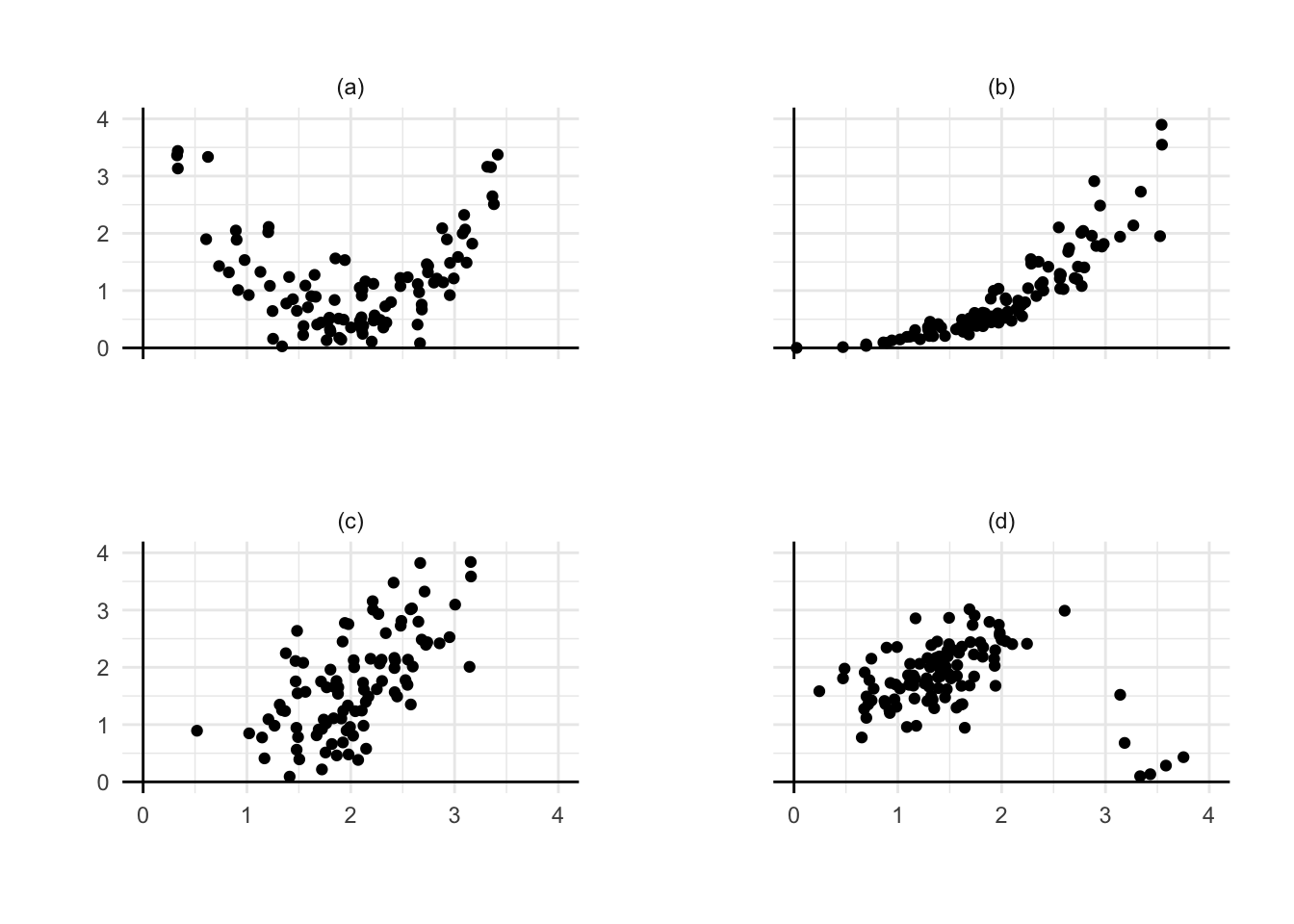
Pytanie 9.1 Spośród czterech wykresów wskaż ten, do którego najlepiej pasuje model liniowy. W pozostałych przypadkach wyjaśnij, dlaczego prosta regresja liniowa może się nie sprawdzić i zaproponuj, jak można sobie z tym poradzić.
Pytanie 9.2 W badaniu Pearsona synowie ojców o wzroście 182 cm mieli średnio 179 cm wzrostu. Prawda czy fałsz: jeśli weźmiemy synów o wzroście 179 cm, to ich ojcowie będą mieli średnio około 182 cm wzrostu. Krótko uzasadnij.
Pytanie 9.3 W badaniu „Diagnoza Społeczna” mężczyźni o wzroście 190 cm ważyli średnio 92 kg. Prawda czy fałsz (uzasadnij): mężczyźni ważący 92 kg musieli mieć średnio 190 cm wzrostu.
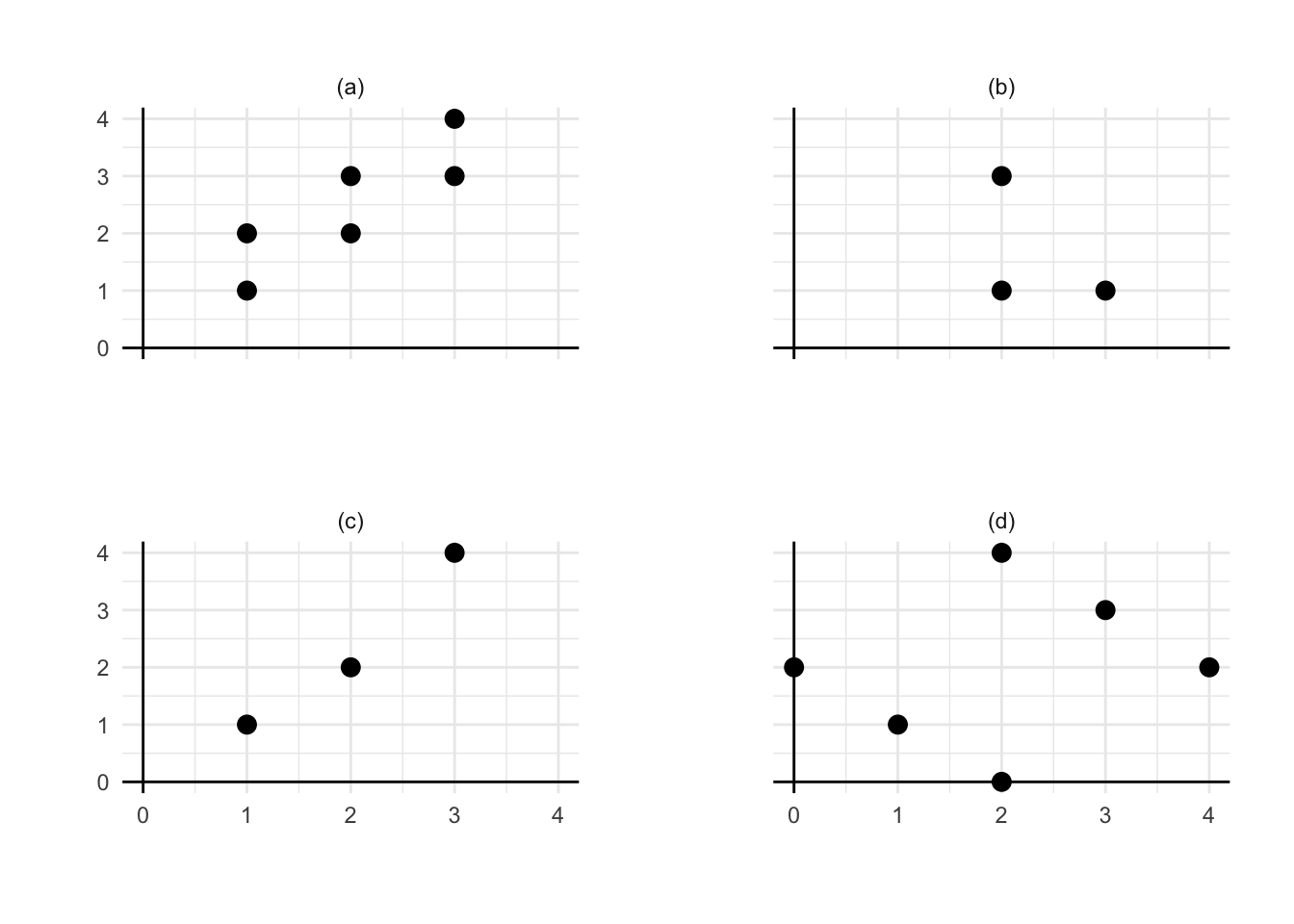
Pytanie 9.4 Na każdym z paneli narysuj ręcznie przybliżoną prostą regresji najmniejszych kwadratów na podstawie przedstawionych danych.
Pytanie 9.5 (Freedman, Pisani, and Purves 2007) W badaniu stabilności ilorazu inteligencji (IQ) duża grupa osób została przebadana dwukrotnie: w wieku 18 lat oraz ponownie w wieku 35 lat. Otrzymano następujące wyniki:
W wieku 18 lat: średni wynik = 100, SD = 15
W wieku 35 lat: średni wynik = 100, SD = 15
Korelacja między wynikami wynosiła 0,80.
Oszacuj średni wynik w wieku 35 lat dla wszystkich osób, które uzyskały 115 punktów w wieku 18 lat.
Stosując model regresji, oszacuj wynik w wieku 35 lat dla osoby, która uzyskała 115 punktów w wieku 18 lat.
Jaka jest różnica między szacowaniem średniej dla istniejącej grupy a przewidywaniem?
9.10.2 Pytania testowe
Pytanie 9.6 W pewnej grupie studentów wynik egzaminu to średnio 60 punktów z odchyleniem standardowym 12, wyniki zaliczenia laboratoriów mają taki sam rozkład. Korelacja między wynikami testu laboratoryjnego a wynikami egzaminu wynosi około 0,50. Korzystając z regresji liniowej, oszacuj średni wynik egzaminu dla studentów, których wyniki testu laboratoryjnego były następujące:
60 punktów:
72 punkty:
36 punktów:
54 punkty:
90 punktów:
Pytanie 9.7 W badaniu 1000 par małżeńskich otrzymano następujące wyniki: średni wzrost męża: 178 cm (odchylenie standardowe = 7 cm), średni wzrost żony: 167 cm (odchylenie standardowe = 6 cm). Współczynnik korelacji wzrostu żony i męża wynosi około 0,25.
Oszacuj (średni) wzrost żony, jeśli wzrost męża wynosi:
178 cm:
171 cm:
192 cm:
174,5 cm:
188,5 cm:
9.11 Zadania
Zadanie 9.1 Wykorzystując dane Galtona, zbuduj model regresji przewidujący wzrost syna na podstawie wzrostu ojca.
Ile w dopasowanym modelu wynoszą punkt przecięcia, współcznnik nachylenia, odchylenie standardowe reszt?
Podaj interpretację współczynnika nachylenia.
Czy punkt przecięcia w tym modelu ma sensowną interpretację?
Jaki przeciętny wzrost synów model przewiduje dla ojców o wzroście 180 cm?
Przedstaw model na wykresie.
Zadanie 9.2 Na podstawie danych o polskich małżeństwach z Diagnozy Społecznej 2015 (husband-wife) sprawdź, używając modelu prostej regresji liniowej, w jaki sposób dochód zależy od wzrostu – osobno dla kobiet (żon) i mężczyzn (mężów). Czy zależność jest istotna statystycznie? Ile wynosi współczynnik korelacji Pearsona? Ile wynosi R-kwadrat? Zinterpretuj uzyskane wyniki.
Zadanie 9.3 Zaproponuj inny model prostej regresji liniowej na podstawie danych w zbiorze husband-wife. Zweryfikuj na wykresie, czy regresja liniowa dobrze opisuje związek między zmiennymi. Podaj interpretację wyrazu wolnego (określ, czy ma sens), współczynnika nachylenia, odchylenia standardowego reszt, współczynnika determinacji R-kwadrat.
Zadanie 9.4 Podczas warsztatów ze statystyki dla dzieci organizowanych w ramach Bałtyckiego Festiwalu Nauki zatytułowanych „jak zważyć psa linijką” jednym z zadań jest oszacowanie masy psa na podstawie jego wielkości.
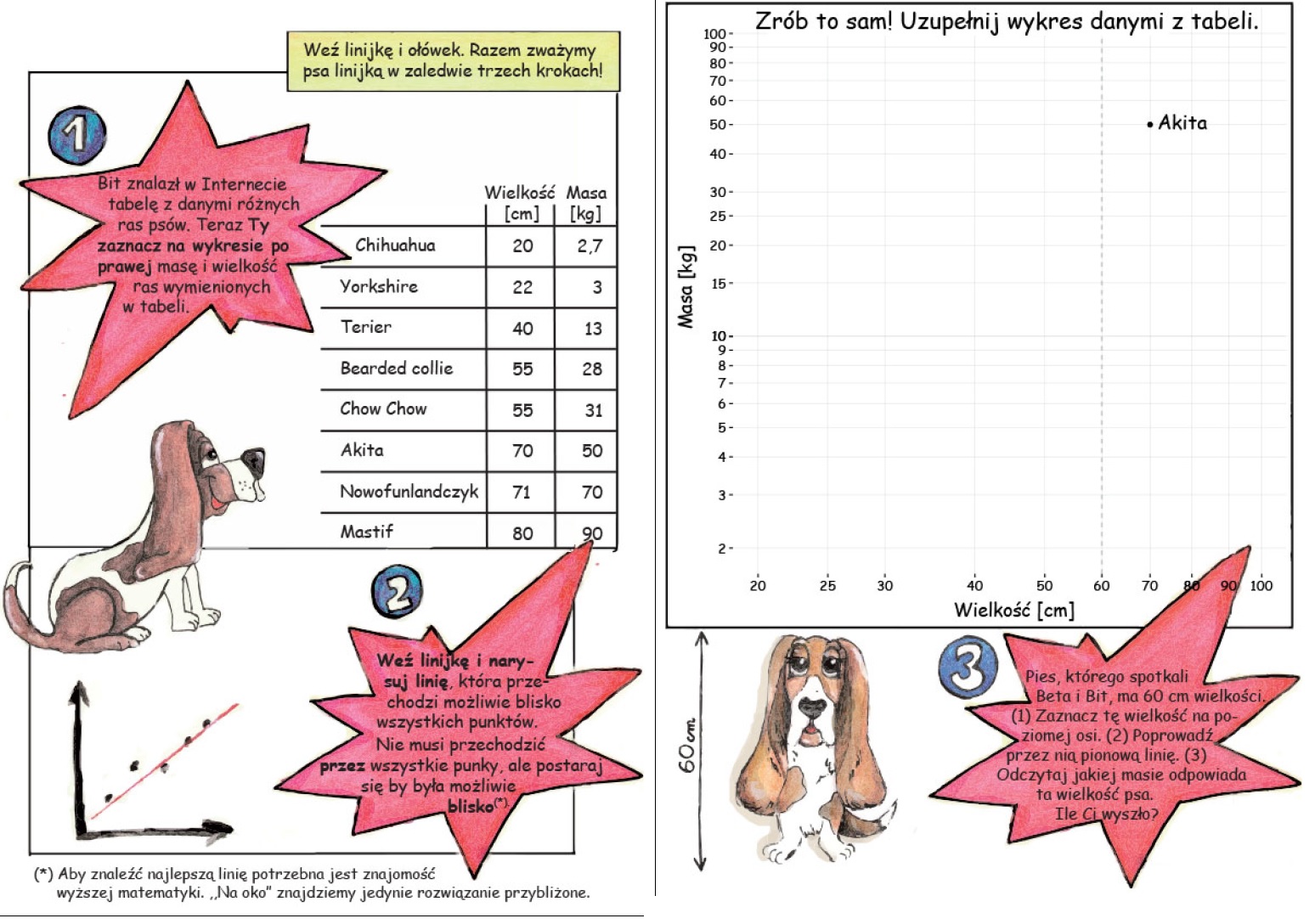
Załóżmy, że zgodnie z przedstawionym powyżej fragmentem komiksu mamy dane o kilku psach, zaś wielkość psa, którego masy nie znamy, wynosi 60 cm.
Należy oszacować masę psa, używając modelu regresji prostej „log-log” (czyli na zmiennych zlogarytmowanych – proszę zwrócić uwagę na skalę w komiksie).
Zadanie 9.5 Wykorzystaj dane z zadania 8.1, żeby na podstawie modelu regresji uwzględniającego wszystkie hrabstwa (counties) z wyłączeniem Palm Beach oszacować liczbę nadmiarowych głosów oddanych na Pata Buchanana.