Rozdział 4 Miary rozproszenia
Opisując rozkład, chcemy opisać nie tylko jego położenie (wykorzystując miary tendencji centralnej), ale także jego rozproszenie (nazywane również zróżnicowaniem, zmiennością, dyspersją lub rozrzutem).
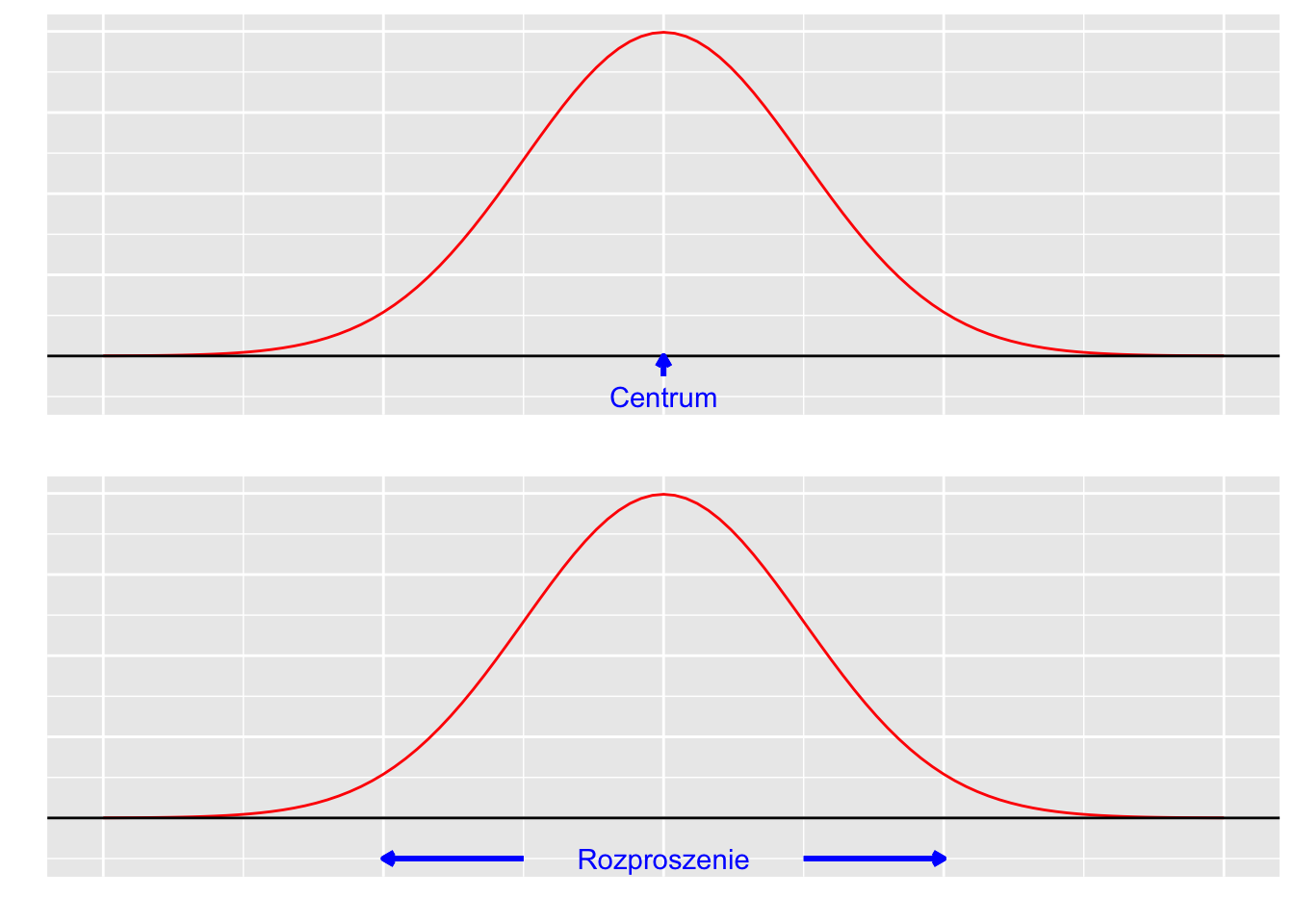
Rysunek 4.1: Tendencja centralna i rozproszenie rozkładu.
4.1 Odchylenie standardowe
Odchylenie standardowe (ang. standard deviation) jest chyba najpopularniejszą miarą rozproszenia rozkładu cechy.
Wzór na odchylenie standardowe pojawia się w dwóch wersjach. W tym skrypcie będziemy je oznaczać3 odpowiednio literami \(\widehat{\sigma}\) i \(s\).
\[\begin{equation} s_X = \sqrt{\frac{\sum_{i=1}^n \left(x_i-\overline{x}\right)^2}{n-1}} \tag{4.1} \end{equation}\]
\[\begin{equation} \widehat{\sigma}_X = \sqrt{\frac{\sum_{i=1}^n \left(x_i-\overline{x}\right)^2}{n}} \tag{4.2} \end{equation}\]
W powyższych wzorach zastosowano subskrypt \(X\), żeby zaznaczyć, że odchylenie standardowe wyznaczamy dla cechy ilościowej \(X\).
Miara \(s\) (wzór (4.1)) nazywana jest odchyleniem standardowym „z próby” lub „dla próby”, dlatego że zwykle jest preferowana, gdy analizowane dane pochodzą z próby.
Miarę \(\widehat{\sigma}\) (wzór (4.2)) również można zastosować dla próby, ale nazywana jest ona często odchyleniem standardowym „dla populacji”. W przypadku populacji tylko ten wzór powinien zostać zastosowany. Jeżeli mamy do czynienia z populacją, pomija się „daszek” nad \(\sigma\).
Jeżeli nie wiadomo, którego wzoru użyć (i ma nikogo, kto by wskazał, którego z tych wzorów oczekuje), stosuje się wzór (4.1).
Własności odchylenia standardowego (prawdziwe dla obu wersji, \(s\) i \(\widehat{\sigma}\)):
Jest wyrażone w tych samych jednostkach co średnia \(\bar{x}\) (i tych samych, w których wyrażone są indywidualne wartości \(x_i\)).
Jest zawsze nieujemne: \(s \geqslant 0\).
Jeżeli każdą z wartości \(x_i\) w zbiorze danych zwiększymy o stałą \(a\), odchylenie standardowe się nie zmieni.
Jeżeli każdą z wartości \(x_i\) w zbiorze danych przemnożymy przez stałą \(k\), nowe odchylenie standardowe wyniesie \(|k|\cdot s\).
4.1.1 Odchylenie standardowe w oprogramowaniu
W języku R funkcja sd() oblicza odchylenie standardowe \(s\) według wzoru (4.1). Wzoru na \(\widehat{\sigma}\) (4.2) nie ma w standardowych pakietach R i należy napisać własną funkcję lub zainstalować dodatkowy pakiet. Brak funkcji obliczającej \(\widehat{\sigma}\) w standardzie R może stanowić dodatkową wskazówkę dotycząca tego, który z wzorów jest zwykle używany i preferowany.
W arkuszach kalkulacyjnych odchylenie standardowe \(s\) („dla próby”) wyznaczamy za pomocą funkcji ODCH.STANDARDOWE (STDEV) – arkusze Google, Excel lub (równoznacznie) ODCH.STANDARD.PRÓBKI (STDEV.S) – arkusze Google, Excel.
Odchylenie standardowe \(\widehat{\sigma}\) „dla populacji” można obliczyć za pomocą funkcji ODCH.STANDARD.POPUL (STDEVP) – arkusze Google, Excel albo ODCH.STAND.POPUL (STDEV.P) – arkusze Google, Excel.
4.1.2 Wariancja
Odchylenie standardowe to pierwiastek z wariancji. Innymi słowy: wariancja to odchylenie standardowe do kwadratu.
Wzory na wariancję są, jak się można domyślić, również dwa:
\[\begin{equation} \widehat{\sigma}^2_X = \frac{\sum_{i=1}^n \left(x_i-\overline{x}\right)^2}{n} \tag{4.3} \end{equation}\]
\[\begin{equation} s^2_X = \frac{\sum_{i=1}^n \left(x_i-\overline{x}\right)^2}{n-1} \tag{4.4} \end{equation}\]
4.1.3 Współczynnik zmienności
Współczynnik zmienności, który jest stosunkiem odchylenia standardowego do średniej, może być w niektórych sytuacjach lepszym miernikiem zmienności.
Jego wzór dla próby to:
\[\begin{equation} V_X = \frac{s_X}{\overline{x}} \tag{4.5} \end{equation}\]
Współczynnika zmienności możemy używać w przypadku zmiennych ilościowych na skali ilorazowej, które przyjmują wyłącznie (albo z reguły) wartości dodatnie.
4.1.4 Wykorzystanie odchylenia standardowego
Odchylenie standardowe jest miarą rozproszenia. W statystyce opisowej używamy tej miary na przykład:
porównując rozproszenie w różnych grupach (bezpośrednio lub w liczbach względnych, korzystając ze współczynnika zmienności),
opisując cechy mające w przybliżeniu rozkład normalny; w takiej sytuacji do opisu rozkładu wystarczą dwie wartości: średnia i odchylenie standardowe,
wyznaczając siłę efektu d Cohena (standaryzowaną różnicę pomiędzy średnimi dwóch grup),
wyznaczając standardyzowane wartości „z” (z-scores),
identyfikując wartości skrajne, odstające.
4.1.5 Odchylenie standardowe nie jest średnim odchyleniem
Można zaproponować inną miarę zmienności: średnie odchylenie, a dokładniej średnie bezwzględne odchylenie od średniej (ang. mean absolute deviation, MAD).
\[\begin{equation} MAD_x = \frac{\sum_{i=1}^n |x_i-\overline{x}|}{n} \tag{4.6} \end{equation}\]
Zarówno odchylenie standardowe, jak i MAD mierzą rozproszenie danych, jednak robią to w odmienny sposób. Średnie bezwzględne odchylenie oblicza średnią wartość wszystkich bezwzględnych odchyleń od średniej (lub mediany). Daje ono bezpośrednią interpretację tego, jak daleko — przeciętnie — obserwacje znajdują się od wartości centralnej. Odchylenie standardowe natomiast opiera się na kwadratach odchyleń od średniej. Ze względu na podnoszenie odchyleń do kwadratu większe różnice mają silniejszy wpływ na wynik. W konsekwencji odchylenie standardowe jest bardziej wrażliwe na wartości skrajne niż średnie odchylenie i zazwyczaj przyjmuje wartości większe niż MAD.
4.2 Rozstęp międzykwartylowy
Inną popularną miarą rozproszenia opartą na miarach położenia jest rozstęp międzykwartylowy (ang. IQR):
\[\begin{equation} IQR = Q_3 - Q_1 \tag{4.7} \end{equation}\]
gdzie \(Q_1\) to kwartyl pierwszy, a \(Q_3\) to kwartyl 3.
4.2.1 Odchylenie ćwiartkowe i pozycyjny współczynnik zmienności
Niekiedy w polskiej literaturze wprowadza się odchylenie ćwiartkowe i pozycyjny współczynnik zmienności. Odchylenie ćwiartkowe to połowa IQR:
\[Q = IQR/2 \tag{4.8}\]
Pozycyjny współczynnik zmienności to iloraz odchylenia ćwiartkowego i mediany:
\[V = Q/Me \tag{4.9}\]
4.3 Wykres pudełkowy
IQR i wartości miar położenia pozwalają stworzyć wykres pudełkowy (wykres skrzynkowy, wykres ramka-wąsy, ang. boxplot lub box-and-whiskers plot). Na tym wykresie przedstawia się najczęściej medianę, kwartyl pierwszy, kwartyl trzeci, a także minimum i maksimum.
Dość często minimum i maksimum wyznacza się z pominięciem wartości odstających (ang. outliers), które osobno zaznacza się na wykresie w formie punktów. Typowa definicja obserwacji odstającej w tym kontekście zakłada, że wartości odstające są albo mniejsze niż \(Q_1 - 1{,}5\cdot IQR\), albo większe niż \(Q_3 + 1{,}5\cdot IQR\). Oczywiście można przyjąć inne definicje wartości odstających.
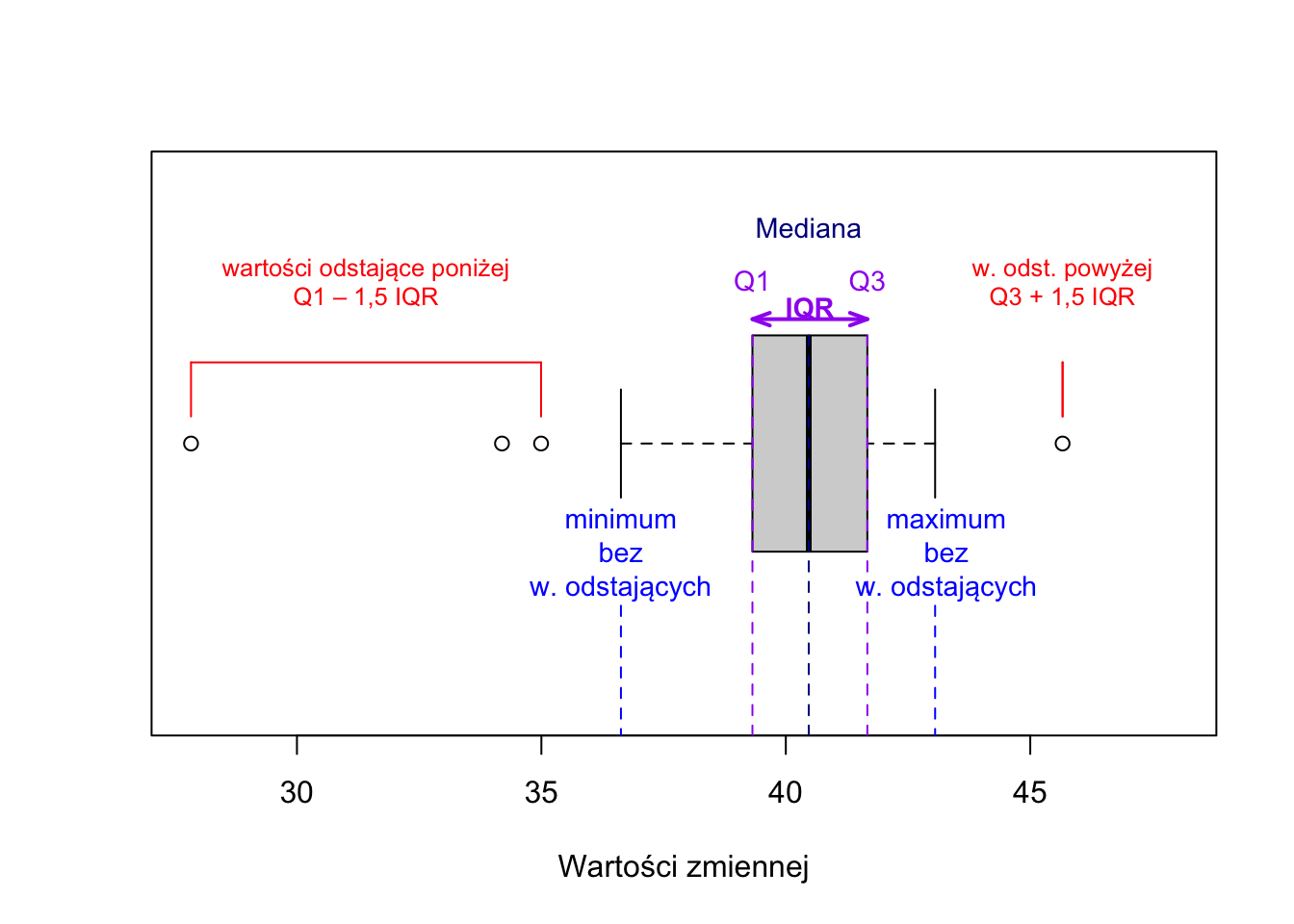
Rysunek 4.2: Budowa wykresu pudełkowego (ramka-wąsy).
4.4 Linki
Eksploracja i wizualizacja danych ilościowych - aplikacja webowa: https://istats.shinyapps.io/EDA_quantitative/
Piotr Szulc – konsekwencje większego rozrzutu: https://danetyka.com/konsekwencje-wiekszego-rozrzutu/
Piotr Szulc – dlaczego liczymy odchylenie standardowe? https://danetyka.com/dlaczego-odchylenie-standardowe/
4.5 Pytania do dyskusji
Pytanie 4.1 Dlaczego współczynnik zmienności jest nieodpowiednią miarą oceny zróżnicowania zimowych temperatur w stopniach Celsjusza w polskim mieście?
4.6 Pytania testowe
Pytanie 4.2 (Freedman, Pisani, and Purves 2007)Poniżej przedstawiono dwa szkice histogramów (funkcji gęstości). Która zmienna jest bardziej rozproszona?
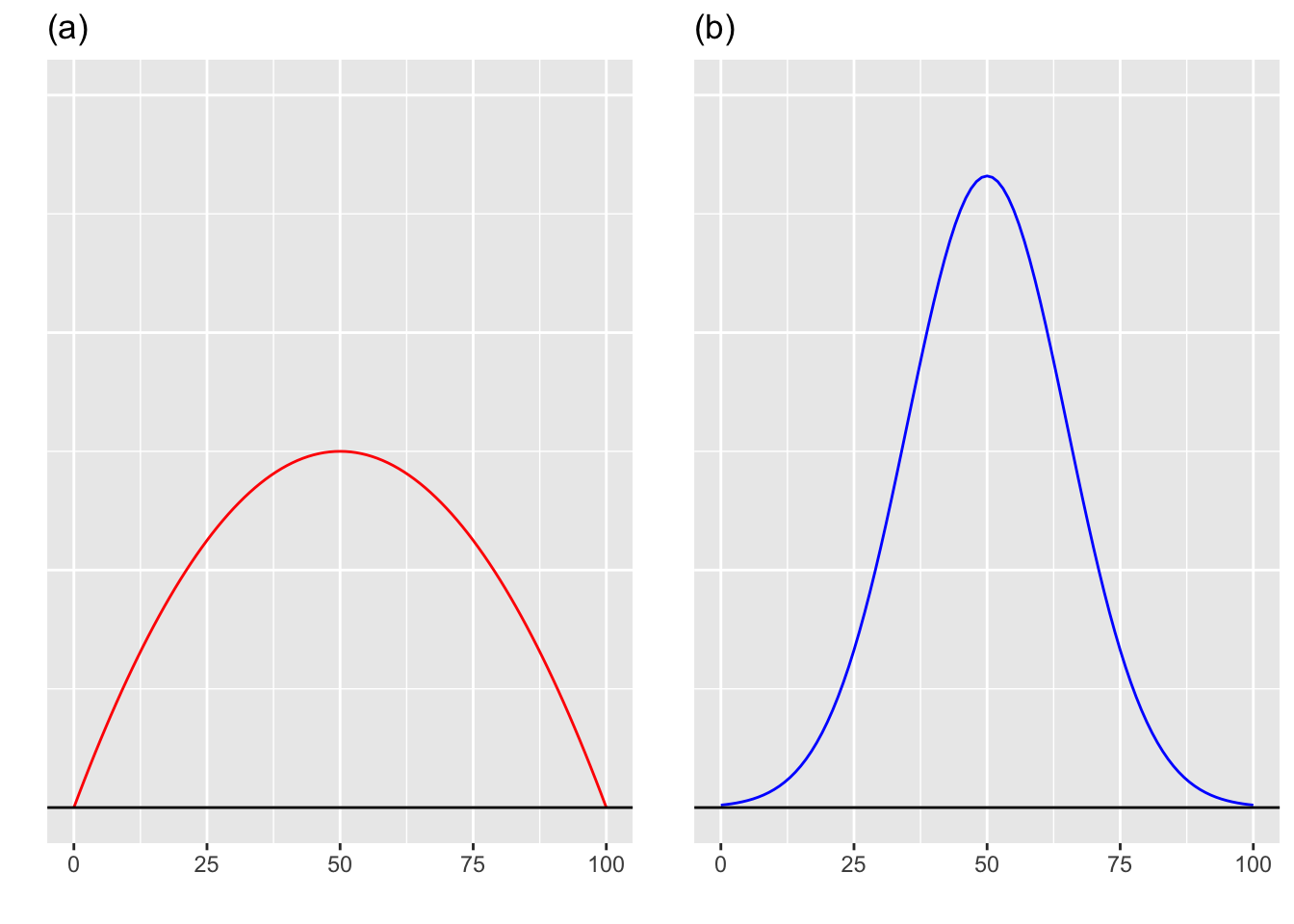
Pytanie 4.3 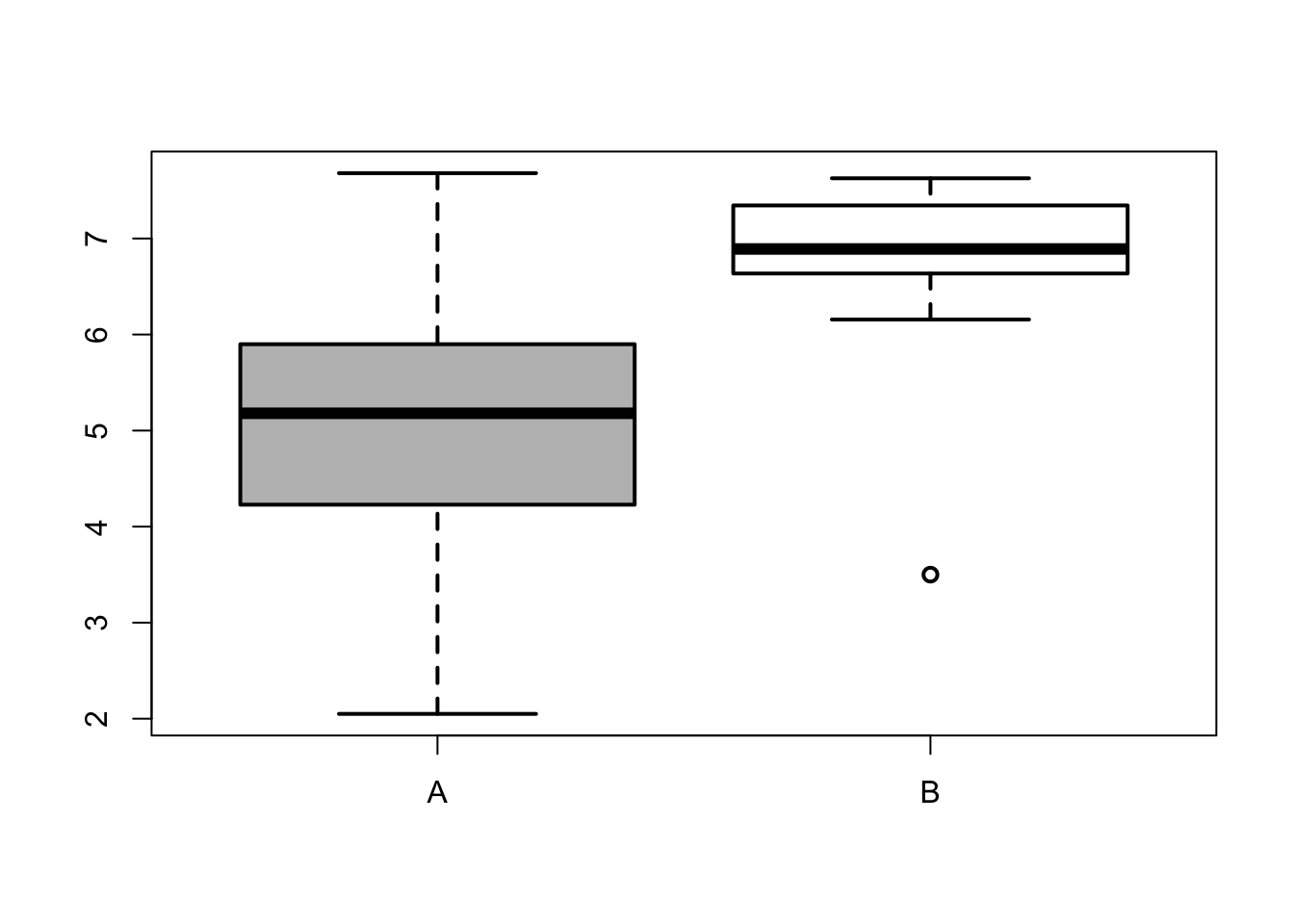
Rozkład danych dla grup (A) i (B) przedstawiono z wykorzystaniem wykresów pudełkowych. Które z poniższych stwierdzeń jest prawdziwe:
Pytanie 4.4 Przyporządkuj wykresy pudełkowe odpowiadające histogramom:
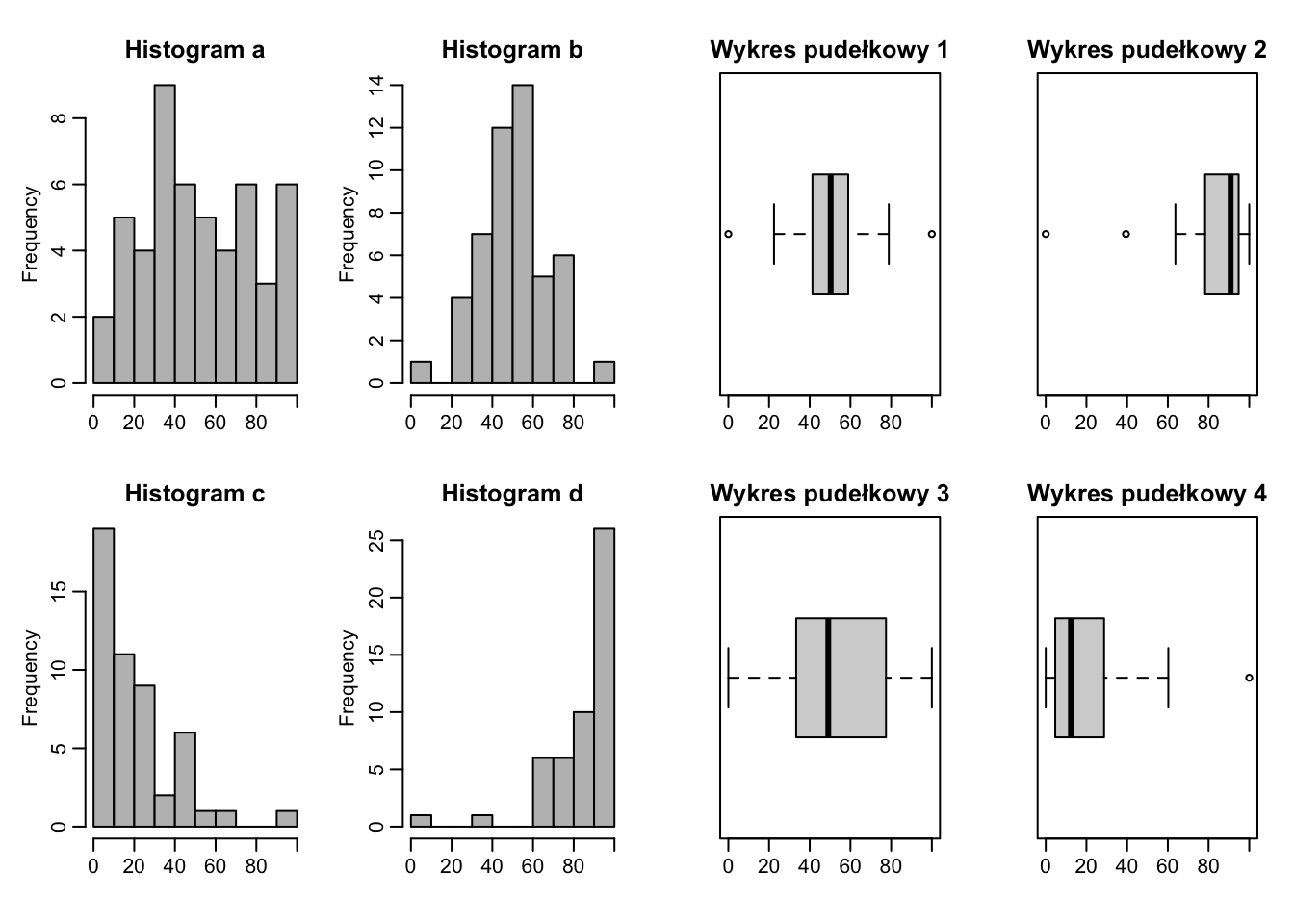
Histogram (a) Histogram (b)
Histogram (c) Histogram (d)
Pytanie 4.5 Odchylenie standardowe (\(\widehat{\sigma}\)) następującego zbioru danych: 1,2,3,4,5,6,7 wynosi 2. Ile wynosi odchylenie standardowe zbioru: 3,6,9,12,15,18,21?
4.7 Zadania
Zadanie 4.1 Wybierz jeden z poniższych zbiorów danych i najpierw oblicz „populacyjną” wersję odchylenia standardowego (\(\widehat{\sigma}\)) samodzielnie (bez użycia komputera). Następnie zweryfikuj otrzymany wynik przy użyciu wybranego oprogramowania.
1, 7, 9, 10, 13
1, 1, 11, 11, 16
1, 1, 2, 4, 7, 7, 9, 13
1, 2, 5, 6, 7, 8, 9, 10
Zadanie 4.2 Wybierz jeden z poniższych zbiorów danych i najpierw oblicz „próbkową” wersję odchylenia standardowego (\(s\)) samodzielnie (bez użycia komputera). Następnie zweryfikuj otrzymany wynik przy użyciu wybranego oprogramowania.
1, 7, 13, 17
1, 8, 10, 12, 14
1, 9, 10, 12, 16, 18
1, 4, 5, 6, 6, 8, 15, 19
Zadanie 4.3 Z danych GUS wynika, że w Polsce jest 16 miejscowości (miast i wsi) o nazwie Dobra. Na podstawie poniższej tabeli przygotuj wykres pudełkowy podsumowujący populację (liczbę mieszkańców) tych miejscowości.
| miejscowość | ludność |
|---|---|
| wieś Dobra, woj. zachodniopom., pow. policki | 4276 |
| wieś Dobra, woj. małop., pow. limanowski | 3217 |
| miasto Dobra, woj. zachodniopom., pow. łobeski | 2103 |
| miasto Dobra, woj. wielkop., pow. turecki | 1358 |
| wieś Dobra, woj. dolnośl., pow. bolesławiecki | 1115 |
| wieś Dobra, woj. opolskie, pow. krapkowicki | 797 |
| wieś Dobra, woj. łódzkie, pow. zgierski | 617 |
| wieś Dobra, woj. podkarp., pow. przeworski | 468 |
| wieś Dobra, woj. dolnośl., pow. oleśnicki | 364 |
| wieś Dobra, woj. podkarp., pow. sanocki | 286 |
| wieś Dobra, woj. śląskie, pow. zawierciański | 276 |
| wieś Dobra, woj. świętokrz., pow. staszowski | 261 |
| wieś Dobra, woj. łódzkie, pow. łaski | 246 |
| wieś Dobra, woj. pomorskie, pow. słupski | 102 |
| wieś Dobra, woj. mazow., pow. płocki | 86 |
| wieś Dobra, woj. wielkop., pow. poznański | 76 |
Zadanie 4.4 Stwórz wykres pudełkowy dla kwoty zamówienia na podstawie danych o zamówieniach ze sklepu internetowego orders.csv
Zadanie 4.5 Porównaj graficznie prędkość samochodów osobowych i jednośladów wykorzystując dwa położone obok siebie wykresy pudełkowe. Dane SpeedRadarData.csv
Literatura
Uwaga! Nie są to oznaczenia powszechnie stosowane — w różnych tekstach można spotkać różne symbole. Zastosowany wzór należy rozpoznać z kontekstu (często autor podaje go wprost).↩︎