Rozdział 3 Miary tendencji centralnej i miary pozycyjne
3.1 Średnia
3.1.1 Średnia arytmetyczna
Średnia arytmetyczna to najprostsze i podstawowe narzędzie podsumowujące położenie rozkładu cechy. Jeżeli mówimy po prostu „średnia”, najczęściej chodzi nam właśnie o średnią arytmetyczną.
Średnia arytmetyczna z \(n\) wartości (oznaczanych od \(x_1\) do \(x_n\)) wynosi:
\[\begin{equation} \overline{x} = \frac{\sum_{i=1}^n x_i}{n} \tag{3.1} \end{equation}\]
Można powiedzieć, że średnia jest środkiem ciężkości zbioru danych.
Typowe własności:
Suma odchyleń \((\overline{x}-x_i)\) od średniej jest równa zero.
Średnia arytmetyczna to taka liczba, że suma kwadratów różnic między nią a każdą z wartości \(x_i\) (czyli następująca suma: \(\sum_i(x_i-\overline{x})^2\)) jest najmniejsza.
Jeżeli każdą z wartości \(x_i\) powiększymy o stałą \(a\), to nowa średnia wyniesie \(\overline{x}+a\).
Jeżeli każdą z wartości \(x_i\) pomnożymy przez stałą \(k\), to nowa średnia wyniesie \(k\overline{x}\).
3.1.2 Ważona średnia arytmetyczna
Niekiedy liczbom z opisywanego zbioru przypisujemy różne wagi (\(x_1\) uwzględniamy z wagą \(w_1\), \(x_2\) z wagą \(w_2\), itd.). Wagi powinny sumować się do jedności: \(\sum_i w_i=1\). Jeżeli mamy wagi \(w^*_i\), które nie sumują się do 1, można je sprowadzić do wag sumujących się do 1 za pomocą wzoru \(w_i = w^*_i / \sum_i w^*_i\).
Jeżeli wagi sumują się do 1, arytmetyczną średnią ważoną wyznaczamy na podstawie wzoru:
\[\overline{x}_{\text{ważona}} =\sum_{i=1}^n x_iw_i \tag{3.2}\]
Jeżeli wszystkie wagi są równe, arytmetyczna średnia ważona jest równa zwykłej średniej arytmetycznej.
Jeżeli nasze dane są w formie szeregu rodzielczego punktowego (zob. 2.1.2), można użyć średniej ważonej z wagami do wyznaczenia średniej arytmetycznej danych:
\[ \overline{x} =\frac{\sum_{j=1}^k x_j n_j}{n} \tag{3.3}\]
W powyższym wzorze \(x_j\) (\(j = 1, ..., k\)) to oznaczenia poszczególnych wartości (punktów danych), \(n_j\) to liczba wystąpień \(j\)-tej wartości, zaś \(n\) to łączna liczba obserwacji. Wagi w tym przypadku to \(w_j = n_j/n\).
3.1.3 Średnia harmoniczna
Średnią harmoniczną wyznaczamy za pomocą następującego wzoru:
\[ H = \frac{n}{\sum_{i=1}^n\frac{1}{x_i}} \tag{3.4}\]
Wzór na ważoną średnią harmoniczną (dla wag sumujących się do jedności):
\[ H_{\text{ważona}} = \frac{1}{\sum_{i=1}^n\frac{w_i}{x_i}} \tag{3.5}\]
3.1.4 Średnia geometryczna
Średnia geometryczna wyznaczana jest na podstawie wzoru:
\[ G = \left(x_1\cdot x_2\cdot ... \cdot x_n\right)^{1/n} = \left(\prod_i x_i\right)^{1/n}\]
Średnia geometryczną wykorzystujemy między innymi, aby wyznaczyć średnie tempo wzrostu.
Wzór na średnią geometryczną możemy również zapisać, używając logarytmów i funkcji wykładniczej: \(\text{exp}(x) = e^x\):
\[ G = \text{exp} \left(\frac {1}{n}\sum \limits _{i=1}^{n}\ln x_{i}\right) \tag{3.6}\]
Możliwe jest też wyznaczenie ważonej średniej geometrycznej (wagi \(w_i\) sumują się do jedności):
\[ G = \text{exp} \left(\sum \limits _{i=1}^{n}w_i\ln x_{i}\right) \tag{3.7}\]
3.2 Mediana
Mediana dzieli dany zbiór (próbę, populację) na dwie równe części. Jeżeli posortujemy zbiór liczb, to mediana będzie środkową wartością lub, jeżeli nie ma jednej środkowej obserwacji, średnią arytmetyczną z dwóch środkowych wartości.
Mediana jest mniej wrażliwa na wartości odstające niż średnia arytmetyczna, dlatego lepiej opisuje tendencję centralną (wartość przeciętną) w zbiorze z dużymi skrajnościami i/lub asymetrycznym rozkładem wartości.
Nie jest potrzebna znajomość wszystkich wartości, żeby wyznaczyć medianę. Może to być ważne w analizie przeżycia (np. gdy mierzymy czas życia produktu lub klienta).
Mediana jest mniej wygodna niż średnia arytmetyczna obliczeniach matematycznych. Średnia arytmetyczna jest zwykle preferowana („lepsza” niż mediana) przy wnioskowaniu statystycznym, np. gdy chcemy poznać rozkład w populacji na podstawie próby losowej. Obliczenie mediany wymaga zazwyczaj więcej mocy obliczeniowej i pamięci komputera.
3.2.1 Wyznaczanie przybliżenia mediany z szeregu rozdzielczego przedziałowego
Z danych w postaci szeregu rozdzielczego przedziałowego (czyli pogrupowanych w przedziały klasowe z podanymi liczebnościami) mediany nie da się odczytać „dokładnie”. Można natomiast ją przybliżyć z wykorzystaniem interpolacji liniowej, wykorzystując następujący wzór:
\[ Me = l_M + \left(\frac{n}{2}-n_{M-}\right)\frac{h_M}{n_M} \tag{3.8}\] gdzie:
\(n\) to liczebność badanej zbiorowości,
\(n_M\) to liczebność przedziału medianowego (zawierającego medianę),
\(h_M\) to szerokość przedziału medianowego,
\(l_M\) to dolna granica przedziału medianowego,
\(n_{M-}\) to skumulowana liczebność wszystkich przedziałów poniżej przedziału medianowego.
Warto pamiętać, że stosując taki wzór, w sposób niejawny zakłada się równomierny rozkład wartości wewnątrz przedziału klasowego.
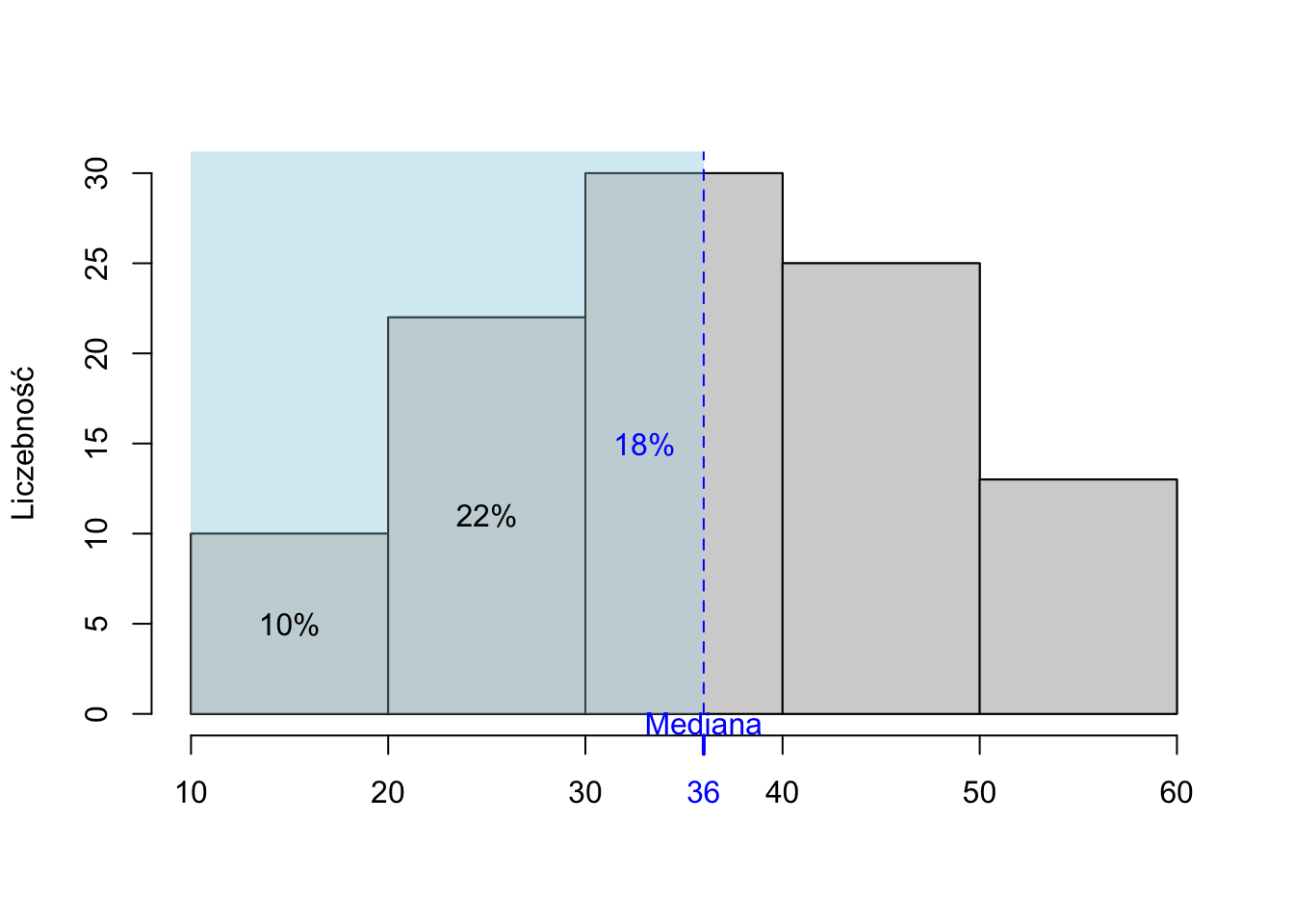
Rysunek 3.1: Przybliżanie mediany na podstawie szeregu przedziałowego – ilustracja.
3.3 Dominanta
Dominanta (moda, modalna) to wartość najczęściej występująca w zbiorze danych (szeregu liczb). Szereg może mieć kilka dominant. Dominantę można wyznaczać dla zmiennych ilościowych i jakościowych.
3.3.1 Wyznaczanie dominanty z szeregu rozdzielczego przedziałowego
Jeżeli liczby dotyczą cechy ciągłej, powyższa definicja dominanty traci rację bytu. W takich sytuacjach często stosuje się inną definicję dominanty: jest to miejsce na osi X, dla którego histogram (stworzony na podstawie szeregu rozdzielczego) osiąga szczyt. W takiej sytuacji dominanta zależy od sposobu pogrupowania danych w klasy oraz od szczegółowego sposobu wyznaczenia miejsca na osi X (środek przedziału lub interpolacja).
Interpolacyjny wzór umożliwiający wyznaczenie dominanty to:
\[ Mo = l_m + \frac{n_m - n_{m-1}}{(n_m - n_{m-1}) + (n_m - n_{m+1})} \cdot h \tag{3.9}\]
gdzie:
\(l_m\) to dolna granica przedziału modalnego (dominującego), czyli takiego, którego liczebność \(n_m\) jest największa,
\(n_m\) to liczebność przedziału modalnego,
\(n_{m-1}\) to liczebność przedziału poprzedzającego przedział modalny,
\(n_{m+1}\) to liczebność przedziału następującego po przedziale modalnym,
\(h\) to szerokość przedziałów.
Powyższy wzór zakłada, że wszystkie szerokości przedziałów \(h\) są równe. Jeżeli nie są równe, potrzebne jest wyznaczenie gęstości liczebności \(d_j=n_j/h_j\) w każdym przedziale \(j=1,2,3,...,k\). W takiej sytuacji wzór ma postać:
\[ Mo = l_m + \frac{d_m - d_{m-1}}{(d_m - d_{m-1}) + (d_m - d_{m+1})} \cdot h_m \tag{3.10}\]
gdzie:
\(l_m\) to dolna granica przedziału modalnego (dominującego), czyli takiego, którego gęstość liczebności \(d_m=n_m/h_m\) jest największa,
\(d_m\) to gęstość liczebności przedziału modalnego,
\(d_{m-1}=n_{m-1}/h_{m-1}\) to gęstość liczebności przedziału poprzedzającego przedział modalny,
\(d_{m+1}=n_{m+1}/h_{m+1}\) to gęstość liczebności przedziału następującego po przedziale modalnym,
\(h_m\) to szerokość przedziału modalnego.
Tak jak w przypadku innych wzorów umożliwiających szacowanie statystyk na bazie szeregu rozdzielczego przedziałowego, zakłada się w sposób niejawny się równomierny rozkład wartości wewnątrz przedziałów.
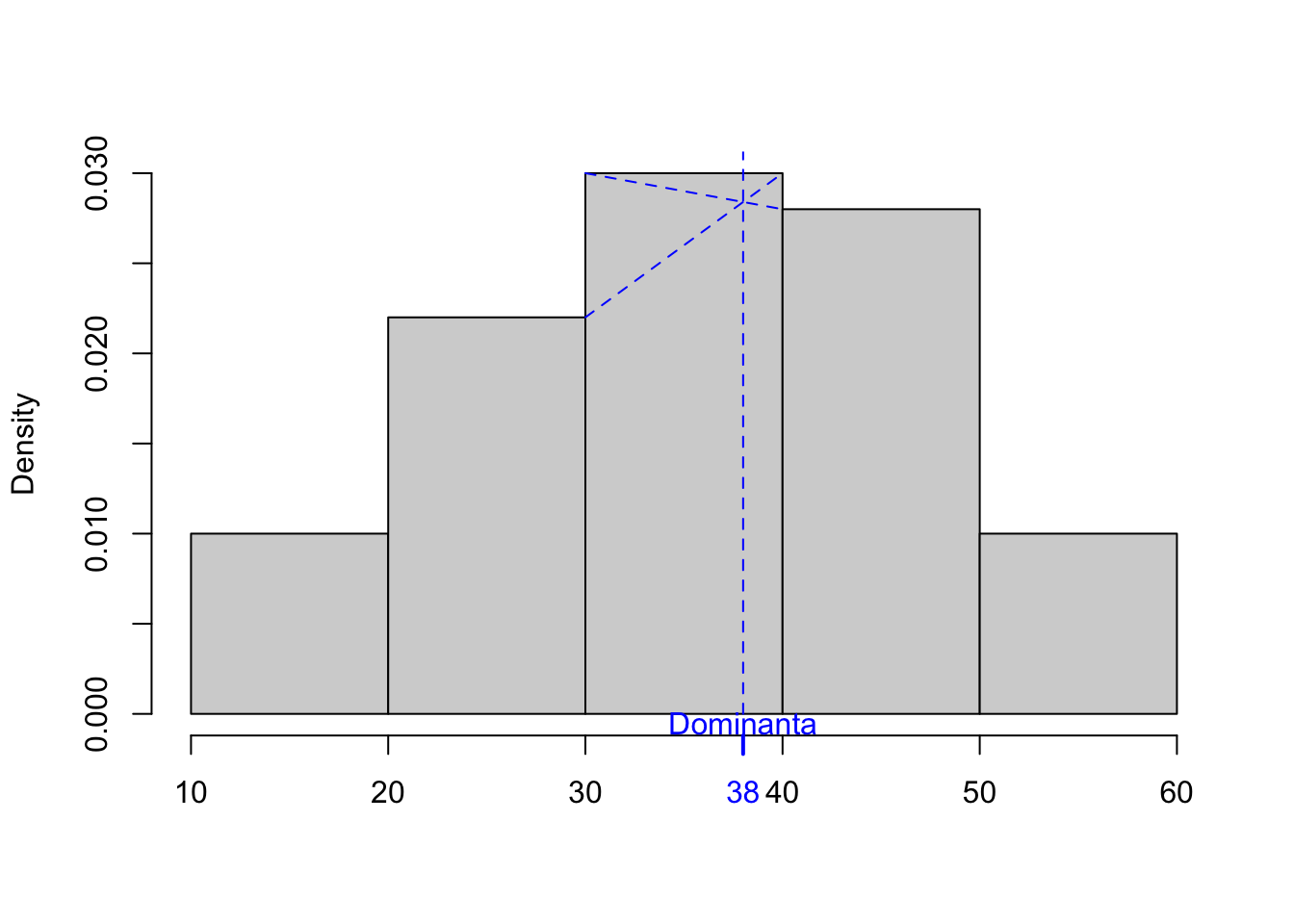
Rysunek 3.2: Przybliżanie dominanty na podstawie szeregu rozdzielczego – ilustracja.
3.3.2 Relacje między dominantą, medianą i średnią arytmetyczną
Jeżeli dane mają (w przybliżeniu) symetryczny i rozkład jest jednomodalny, średnia, mediana i dominanta są (w przybliżeniu) równe.
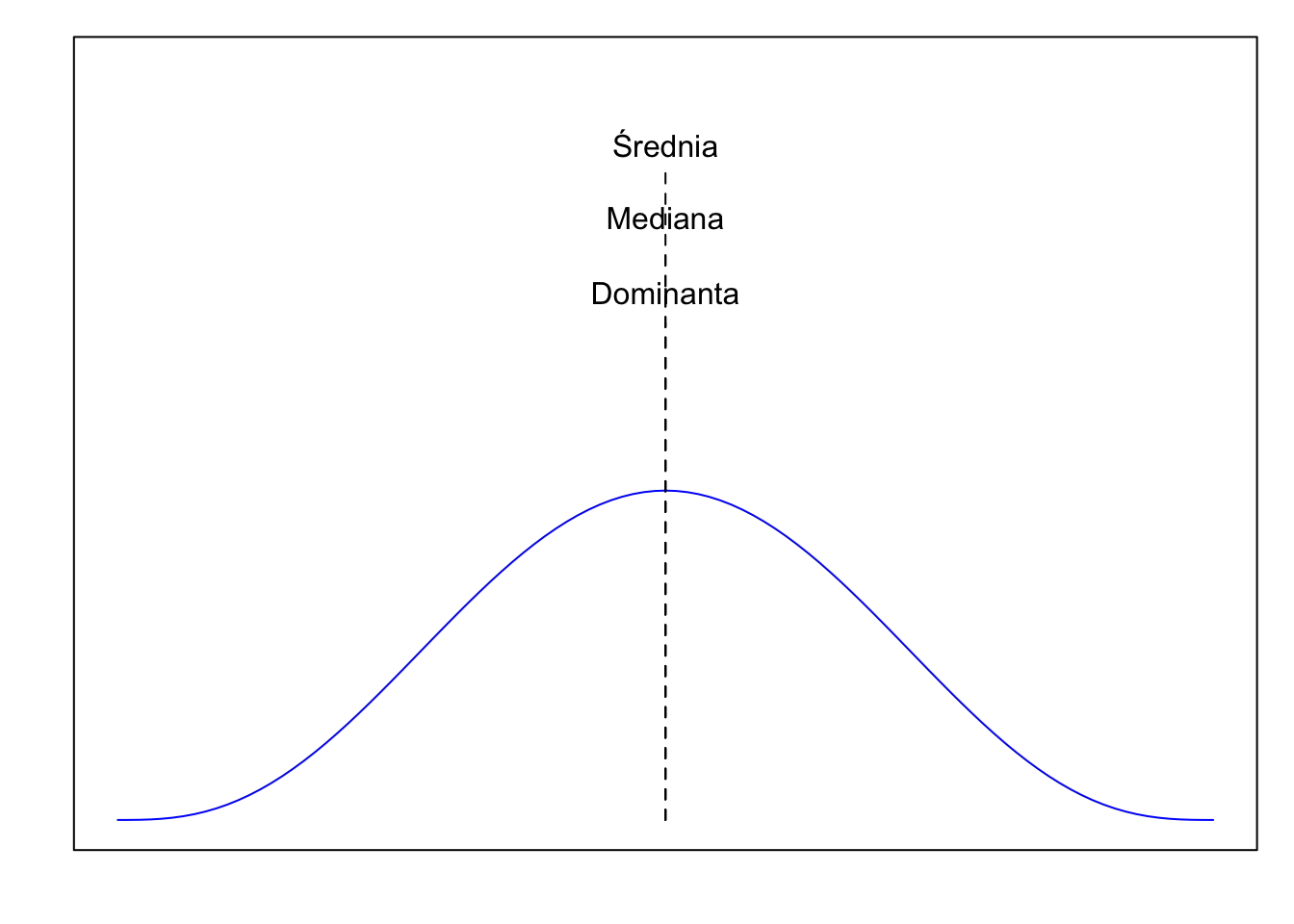
Rysunek 3.3: W jednomodalnym symetrycznym rozkładzie: Dominanta = Mediana = Średnia.
Jeżeli rozkład ma asymetrię dodatnią (jest prawostronnie skośny), często – ale nie zawsze – mamy do czynienia z zależnością: Dominanta < Mediana < Średnia. Ogon po prawej stronie „ciągnie” średnią w stronę większych wartości.
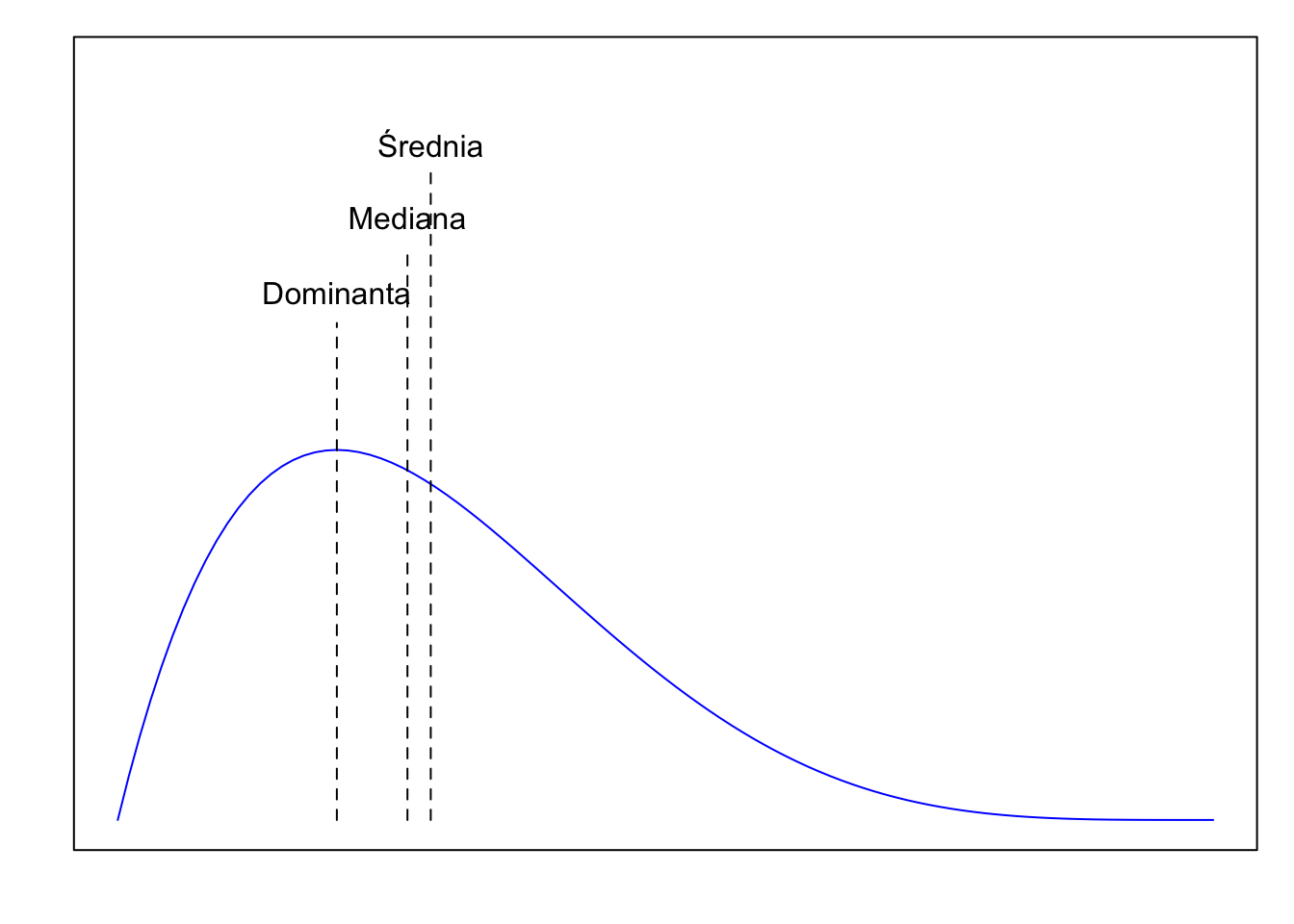
Rysunek 3.4: W rozkładzie o dodatniej asymetrii: Dominanta < Mediana < Średnia.
Jeżeli rozkład ma asymetrię ujemną (jest lewostronnie skośny), często – ale nie zawsze – mamy do czynienia z zależnością: Dominanta > Mediana > Średnia. Ogon po lewej stronie „ciągnie” średnią w stronę mniejszych wartości.
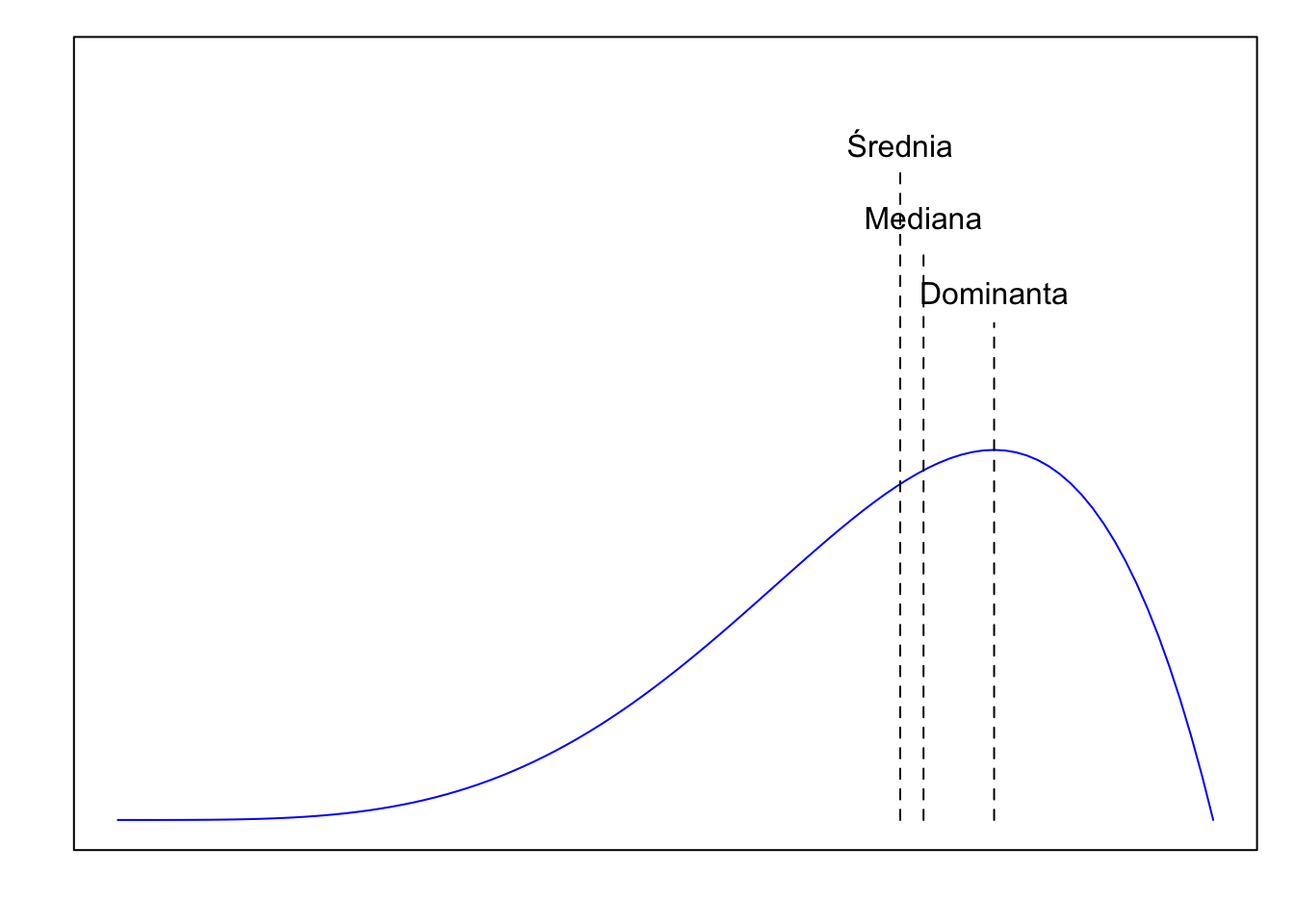
Rysunek 3.5: W rozkładzie o ujemnej asymetrii: Dominanta > Mediana > Średnia.
3.4 Miary pozycyjne (kwantyle)
Miary pozycyjne to miary oparte na uporządkowanym (posortowanym) zbiorze danych. Przykładem takiej miary jest najbardziej znany kwantyl: mediana.
3.4.1 Kwartyle
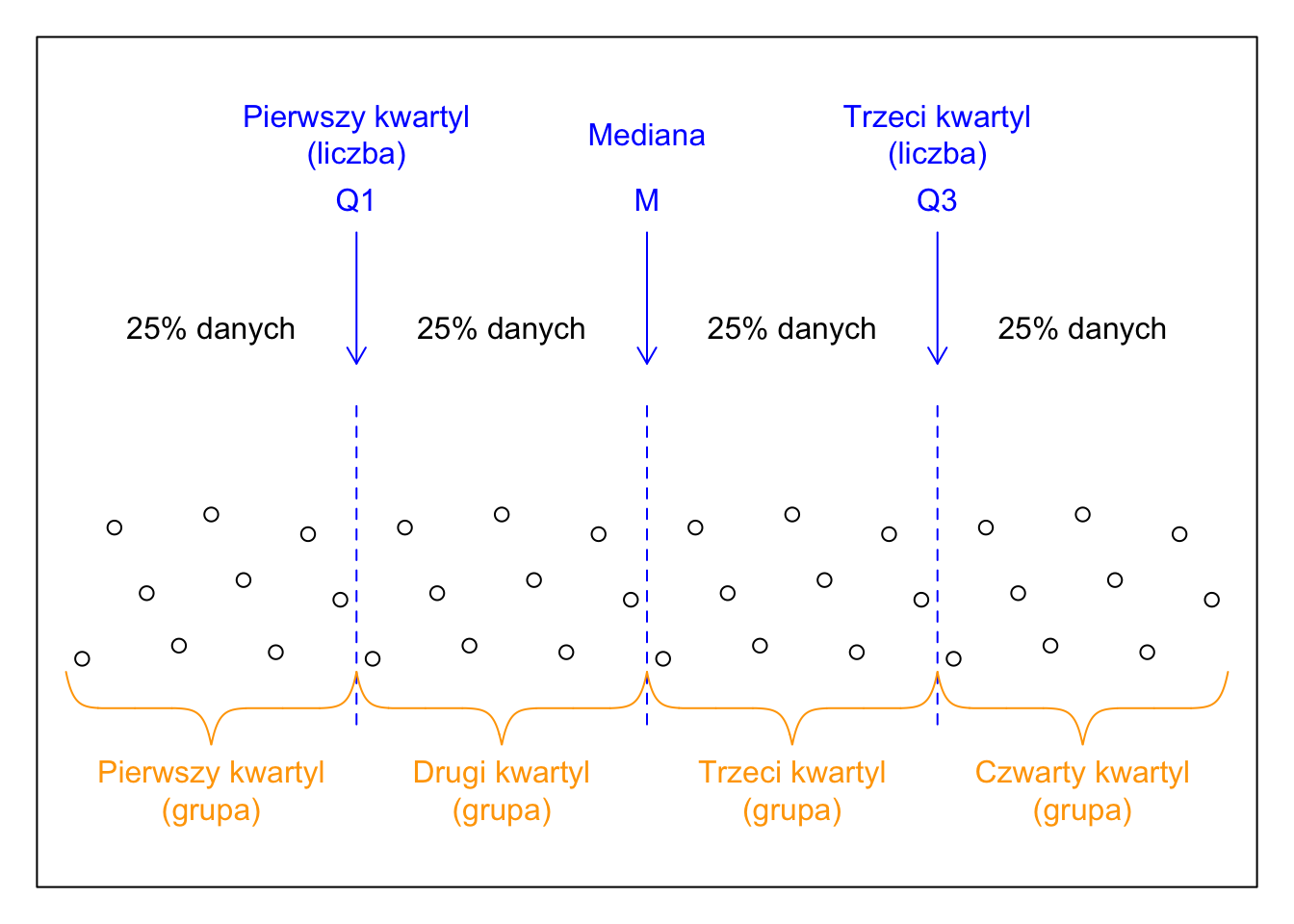
Mediana dzieli dany zbiór (próbę, populację) na dwie równe części. Kwartyle (pierwszy, drugi = mediana i trzeci) dzielą dany zbiór na cztery równe części.
Kwartyl pierwszy (dolny) to (w pierwszym znaczeniu, zob. niżej) liczba, która rozbija zbiór danych na dolne 25% obserwacji i górne 75% obserwacji.
Kwartyl drugi to mediana. Rozbija ona zbiór danych na dolne 50% i górne 50%.
Kwartyl trzeci (górny) to liczba, która rozbija zbiór na dolne 75% obserwacji i górne 25% obserwacji.
3.4.2 Dwa znaczenia słowa kwartyl
Warto przy tej okazji zwrócić uwagę na fakt, że słowo kwartyl (podobnie jak słowa oznaczające niektóre inne kwantyle, np. kwintyl lub decyl) może występować w dwóch znaczeniach:
w pierwszym znaczeniu kwartyl (kwintyl, decyl) to wartość liczbowa oddzielająca określoną frakcję (np. pierwszy kwartyl oddziela dolne 25% )
w drugim znaczeniu kwartyl to obserwacje, które pod względem analizowanej cechy znajdują się w określonej ćwiartce. Aby uniknąć niejednoznaczności, można użyć określenia „grupa kwartylowa”.
Na przykład weźmy dochód dyspozycyjny gospodarstw domowych. Drugi kwartyl to:
w pierwszym znaczeniu – mediana dochodów,
w drugim znaczeniu – te gospodarstwa domowe, których dochód znajduje się w przedziale między pierwszym kwartylem (w pierwszym znaczeniu) a medianą.
3.4.3 Kwintyle
Kwintyle dzielą zbiór danych na 5 grup, np. drugi kwintyl (w pierwszym znaczeniu) dzieli zbiór na dolne 40% i górne 60%.
3.4.4 Decyle
Decyle dzielą zbiór danych na 10 grup. Na przykład 3 decyl dzieli zbiór na dolne 30% i górne 70%.
3.4.5 Percentyle
Percentyle albo centyle dzielą zbiór danych na 100 grup. Przyjmuje się, że analogicznie można zdefiniować percentyle ułamkowe, np. percentyl 97,5 dzieli zbiór danych na dolne 97,5% i górne 2,5%.
Rysunek 3.6: Typowe kwantyle
3.4.6 Wyznaczanie kwantylów w praktyce
W praktyce okazuje się, że definicja przedstawiona powyżej nie jest wystarczająco jednoznaczna. Na przykład, czy da się wyznaczyć na podstawie ogólnej definicji pierwszy kwartyl dla zbioru danych składającego się z jedynie 11 obserwacji?
W poniższej tabeli pokazano wyznaczenie kwartylów dla prostego zbioru danych składającego się z dziesięciu liczb: 1, 1, 2, 2, 4, 5, 6, 7, 9, 10 z wykorzystaniem dziewięciu (!) algorytmów zaimplementowanych w R.
Nie wnikając w zawiłości algorytmów, warto zaznaczyć, że w R i w Excelu/Google (funkcja KWARTYL) domyślnie stosowany jest algorytm 7.
| Numer algorytmu | Kwartyl 1 | Mediana | Kwartyl 3 |
|---|---|---|---|
| type = 1 | 2,000000 | 4,0 | 7,000000 |
| type = 2 | 2,000000 | 4,5 | 7,000000 |
| type = 3 | 1,000000 | 4,0 | 7,000000 |
| type = 4 | 1,500000 | 4,0 | 6,500000 |
| type = 5 | 2,000000 | 4,5 | 7,000000 |
| type = 6 | 1,750000 | 4,5 | 7,500000 |
| type = 7 | 2,000000 | 4,5 | 6,750000 |
| type = 8 | 1,916667 | 4,5 | 7,166667 |
| type = 9 | 1,937500 | 4,5 | 7,125000 |
3.5 Linki
Średnia jako środek ciężkości – wizualizacja: https://www.geogebra.org/m/y4peqgpk
Średnia a mediana – aplikacja webowa: https://istats.shinyapps.io/MeanvsMedian/
Średnia a mediana – danetyka.com: (1) https://danetyka.com/srednia-mediana-efektywnosc/ (2) https://danetyka.com/mediana-srednia/
Asymetria rozkładu a średnia i mediana – symulacja: https://college.cengage.com/nextbook/statistics/utts_13540/student/html/simulation2_3.html
Przykłady siatek centylowych (WHO): https://www.who.int/tools/child-growth-standards/standards/weight-for-age
Przykłady siatek centylowych (Instytut Matki i Dziecka): https://i.wp.pl/a/i/szkola2/pdf/siatki_centylowe.pdf
Średnia geometryczna – rolka: https://www.facebook.com/reel/1304267144759969/?fs=e&s=TIeQ9V&fs=e&fs=e
Średnia harmoniczna – rolka: https://www.facebook.com/share/v/1CxaLRxjJo/?mibextid=wwXIfr
3.6 Pytania do dyskusji
Pytanie 3.1 Czy zmienna jakościowa może mieć modę? Podaj przykład.
Pytanie 3.2 Czy zmienna jakościowa może mieć medianę? Podaj przykład typu zmiennej, dla której można wyznaczyć medianę.
3.7 Zadania
Zadanie 3.1 Dane są następujące obserwacje:
\[x_1 = 2,\; x_2 = 4,\; x_3 = 1,\; x_4 = 3,\; x_5 = 5,\; x_6 = 2,\; x_7 = 4\]
Oblicz:
\(\displaystyle \sum_{i=1}^{7} x_i\:\:\:\:\:\) =
\(\displaystyle \overline{x} =\frac{1}{7}\sum_{i=1}^7 x_i\:\:\:\:\:\) =
\(\displaystyle \sum_{i=1}^{7} x_i^2\:\:\:\:\:\) =
\(\displaystyle \sum_{i=1}^{5} x_i\:\:\:\:\:\) =
\(\displaystyle \sum_{i=1}^{7} (x_i - \overline{x})\:\:\:\:\:\) =
\(\displaystyle \frac{1}{7}\sum_{i=1}^7 x_i+2 \quad\) =
\(\displaystyle \prod_{i=1}^{7} x_i\quad\) =
\(\displaystyle \sum_{i=1}^{7} i\quad\) =
\(\displaystyle \prod_{i=1}^{7} i\quad\) =
Zadanie 3.2 (Freedman, Pisani, and Purves 2007)Która z poniższych dwóch list ma wyższą średnią? Czy są to te same listy? Spróbuj odpowiedzieć bez wykonywania obliczeń.
Lista A: 5, 4, 6, 9, 8
Lista B: 5, 4, 6, 9, 8, 10
Zadanie 3.3 (Freedman, Pisani, and Purves 2007)
Średni wzrost dziesięciu osób w pokoju wynosi 166 cm. Do pokoju wchodzi 11. osoba, mająca 199 cm wzrostu. Oblicz średni wzrost wszystkich 11 osób. cm
Średni wzrost 21 osób w pokoju wynosi 166 cm. Do pokoju wchodzi 22. osoba, mająca 199 cm wzrostu. Oblicz średni wzrost wszystkich 22 osób. cm
Średni wzrost 21 osób w pokoju wynosi 166 cm. Do pokoju wchodzi 22. osoba. Jakiego wzrostu powinna być 22. osoba, żeby zwiększyć średni wzrost osób w pokoju o 3 cm? cm.
Zadanie 3.4
Przez godzinę jechaliśmy z prędkością 60 km/h, przez kolejną godzinę jechaliśmy 120 km/h. Z jaką średnią prędkością jechaliśmy?
Na odcinku 100 km jechaliśmy z prędkością 60 km/h, na odcinku 100 km jechaliśmy z prędkością 120 km/h. Z jaką średnią prędkością jechaliśmy?
Przez 60% czasu (np. 3 z 5 godzin) jechaliśmy z prędkością 60 km/h, przez 40% czasu (np. 2 z 5 godzin) jechaliśmy z prędkością 120 km/h. Z jaką średnią prędkością jechaliśmy?
Przez 60% drogi (np. 300 km) jechaliśmy z prędkością 60 km/h, a przez 40% drogi (np. 200 km) jechaliśmy z prędkością 120 km/h. Z jaką średnią prędkością jechaliśmy?
Zadanie 3.5 Na podstawie danych o zamówieniach ze sklepu internetowego (orders.csv ) oblicz i zinterpretuj medianę kwoty zamówienia, pierwszy kwartyl, trzeci kwartyl, dziesiąty i dziewięćdziesiąty centyl. Ile wynosi IQR?
Zadanie 3.6 Na podstawie danych z radaru (SpeedRadarData.csv ) oblicz i zinterpretuj medianę, dolny i górny kwartyl prędkości (zmienna speed, w km/h) dla:
jednośladów,
samochodów osobowych.
Z czego mogą wynikać różnice?