Rozdział 10 Regresja wieloraka
10.1 Wzór
W wielorakiej regresji liniowej występuje więcej niż jedna zmienna niezależna (wejściowa, objaśniająca) \(X\). Niech liczba zmiennych objaśniających będzie oznaczona przez \(k\). Zmienne objaśniające będą oznaczane jako \(X_1\), ..., \(X_k\). I-tą obserwację zmiennej \(X_2\) będziemy oznaczać \(x_{i2}\) lub \(x_{i,2}\).
Dopasowane równanie wielorakiej regresji liniowej ma postać:
\[\widehat{y_i} = \widehat{\beta}_0 + \widehat{\beta}_1 x_{i1} + \widehat{\beta}_2 x_{i2} + \cdots + \widehat{\beta}_k x_{ik}, \tag{10.1}\]
gdzie \(\widehat{y_i}\) to dopasowana wartość odpowiedzi dla obserwacji \(i\), a \(\widehat{\beta}_0\), \(\widehat{\beta}_1\), \(\ldots\), \(\widehat{\beta}_k\) to oszacowane współczynniki regresji.
Jeśli istnieją dwie zmienne objaśniające (\(k=2\)), równanie regresji (10.1) opisuje płaszczyznę w przestrzeni 3D (patrz rysunek 10.1); jeśli istnieje więcej \(X\), równanie opisuje hiperpłaszczyznę w przestrzeni \((k+1)\)-wymiarowej.
Rysunek 10.1: Trójwymiarowy wykres ilustrujący model regresji wielorakiej z dwoma zmiennymi objaśniającymi.
10.2 Interpretacja
Każdy współczynnik regresji w modelu regresji wielorakiej mierzy oczekiwaną zmianę w zmiennej objaśniajnej, gdy powiązana z nią zmienna objaśniająca wzrośnie o jedną jednostkę, przy zachowaniu wszystkich innych zmiennych objaśniających na stałym poziomie (łac. ceteris paribus).
- Wyraz wolny (\(\widehat{\beta}_0\)):
Punkt przecięcia reprezentuje oczekiwaną wartość zmiennej objaśnianej \(Y\), gdy wszystkie zmienne objaśniające \(X\) są równe zero. W zależności od kontekstu taka wartość może mieć interpretację lub nie.
- Współczynniki nachylenia (\(\widehat{\beta}_1, \widehat{\beta}_2, \dots, \widehat{\beta}_k\)):
Współczynnik \(\hat{\beta}_j\) przedstawia oszacowaną w ramach modelu zmianę przeciętną zmiennej objaśnianej \(Y\) związaną ze wzrostem o jedną jednostkę zmiennej \(X_j\), przy założeniu, że wszystkie inne zmienne (\(X\)) pozostają niezmienione. Konieczność uwzględnienia w interpretacji formuły „ceteris paribus” (wszystko inne bez zmian) odróżnia regresję wieloraką od regresji prostej.
Dopasowane wartości (\(\hat{y}_i\)) leżą na hiperpłaszczyźnie regresji zdefiniowanej równaniem (10.1). Reszty to odchylenia (odległości „w pionie”) obserwowanych wartości zmiennej objaśnianej od tej hiperpłaszczyzny.
Przykład:.
Około 1888 roku zebrano dane z 47 francuskojęzycznych „prowincji” Szwajcarii. Zmienna Fertility (płodność) to indeks płodności, opartym na liczbie dzieci przypadających na kobietę; jest ona wyrażona jako wartość procentowa w stosunku do wysoce płodnej grupy Huterytów, służącej jako punkt odniesienia. Zmienna Education reprezentuje odsetek poborowych z wykształceniem powyżej szkoły podstawowej. Zmienna Infant.Mortality (śmiertelność niemowląt) wskazuje odsetek dzieci, które umierają przed osiągnięciem pierwszego roku życia, w stosunku do żywych urodzeń.
##
## Call:
## lm(formula = Fertility ~ Education + Infant.Mortality, data = swiss)
##
## Residuals:
## Min 1Q Median 3Q Max
## -15.3906 -6.0088 -0.9624 5.8808 21.0736
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 48.8213 8.8904 5.491 0.000001875 ***
## Education -0.8167 0.1298 -6.289 0.000000127 ***
## Infant.Mortality 1.5187 0.4287 3.543 0.000951 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 8.426 on 44 degrees of freedom
## Multiple R-squared: 0.5648, Adjusted R-squared: 0.545
## F-statistic: 28.55 on 2 and 44 DF, p-value: 0.0000000112610.3 Zmienne dychotomiczne w regresji liniowej
Zmienna dychotomiczna (binarna) przyjmuje tylko dwie wartości, zwykle kodowane jako 0 i 1:
\[ x_{i} = \begin{cases} 1 & \text{jeśli cecha jest obecna}, \\ 0 & \text{w przeciwnym razie}. \end{cases}\]
Zmienne dychotomiczne są również nazywane zmiennymi sztucznymi lub zmiennymi wskaźnikowymi. Stosuje się je często w regresji wielorakiej, ponieważ pozwalają na uwzględnienie zmiennych jakościowych – takich jak płeć, grupa poddana leczeniu vs. grupa kontrolna, weekend vs. dzień powszedni, tak/nie itp.
Zmienne dychotomiczne działają podobnie do innych zmiennych objaśniających. Posłuży się przykładem następującego modelu:
\[\widehat{y}_i = \widehat{\beta}_0 + \widehat{\beta}_1 x_{i1} + \widehat{\beta}_2 d_i,\]
gdzie \(x_{i1}\) to wartości zmiennej ciągłej \(X_1\) (np. dochód), a \(d_i\) to wartości zmiennej binarnej \(X_2\) (np. płeć = 1 jeśli kobieta, 0 jeśli mężczyzna).
W tym modelu:
\(\widehat{\beta}_1\) mierzy różnicę między przewidywanymi średnimi wartościami \(Y\), gdy \(X_1\) wzrasta o jedną jednostkę, a wartość \(X_2\) pozostaje stała.
\(\widehat{\beta}_2\) mierzy różnicę między dwiema grupami zmiennej \(X_2\) przy utrzymywaniu stałej wartości \(X_1\).
Przykład:.
Model przewiduje rozpiętość prawej dłoni (Right hand span) na podstawie wzrostu (Height) oraz płci (Gender) na danych zebranych od próby składającej się z 381 studentów. Zgodnie z oszacowanym modelem, dla ustalonej płci przeciętna rozpiętość dłoni zwiększa się o około 0,08 cm (0,8 mm) na każdy dodatkowy centymetr wzrostu.
Po uwzględnieniu wzrostu, przeciętna różnica w rozpiętości dłoni między płciami wynosi około 1,32 cm. Typowa różnica między wartością przewidywaną przez model a rzeczywistą wartością rozpiętości dłoni wynosi około 1,52 cm. Model „wyjaśnia” około 44,5% zróżnicowania rozpiętości dłoni w badanej próbie.
##
## Call:
## lm(formula = right_hand_span ~ height + gender, data = a)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.5086 -0.9920 0.0785 1.0021 4.2563
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.76530 2.11696 2.251 0.025 *
## height 0.08472 0.01253 6.759 0.0000000000527 ***
## genderMale 1.32469 0.23267 5.693 0.0000000250411 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.518 on 378 degrees of freedom
## (2 observations deleted due to missingness)
## Multiple R-squared: 0.4449, Adjusted R-squared: 0.442
## F-statistic: 151.5 on 2 and 378 DF, p-value: < 0.0000000000000002210.4 Notacja macierzowa
Aby przedstawić wzory na oszacowania współczynnika \(\widehat{\beta}\) w regresji wielokrotnej, wprowadzamy następującą notację macierzową:
- Macierz układu \(\mathbf{X}\):
Macierz układu znana jest też pod innymi nazwami (vide wikipedia). Jest to macierz zawierająca wszystkie zmienne objaśniające. Każdy wiersz odpowiada jednej obserwacji, pierwsza kolumna składa się z jedynek (odpowiadających wyrazowi wolnemu), a pozostałych \(k\) kolumn zawiera zaobserwowane wartości zmiennych \(X_1, \ldots, X_k\).
- Wektor odpowiedzi (\(\mathbf{y}\)):
Wektor kolumnowy zawierający zaobserwowane wartości zmiennej objaśnianej (\(Y\)).
W takiej notacji wzór na dopasowany metodą najmniejszych kwadratów wektor \(\widehat{\beta}\) (wektor kolumnowy zawierający oszacowania \(\widehat{\beta}_0, \dots, \widehat{\beta}_k\)) można wyrazić w następujący sposób:
.
\[\widehat{\boldsymbol{\beta}} = (\mathbf{X}^\top \mathbf{X})^{-1}\mathbf{X}^\top \mathbf{y} \tag{10.2}\]
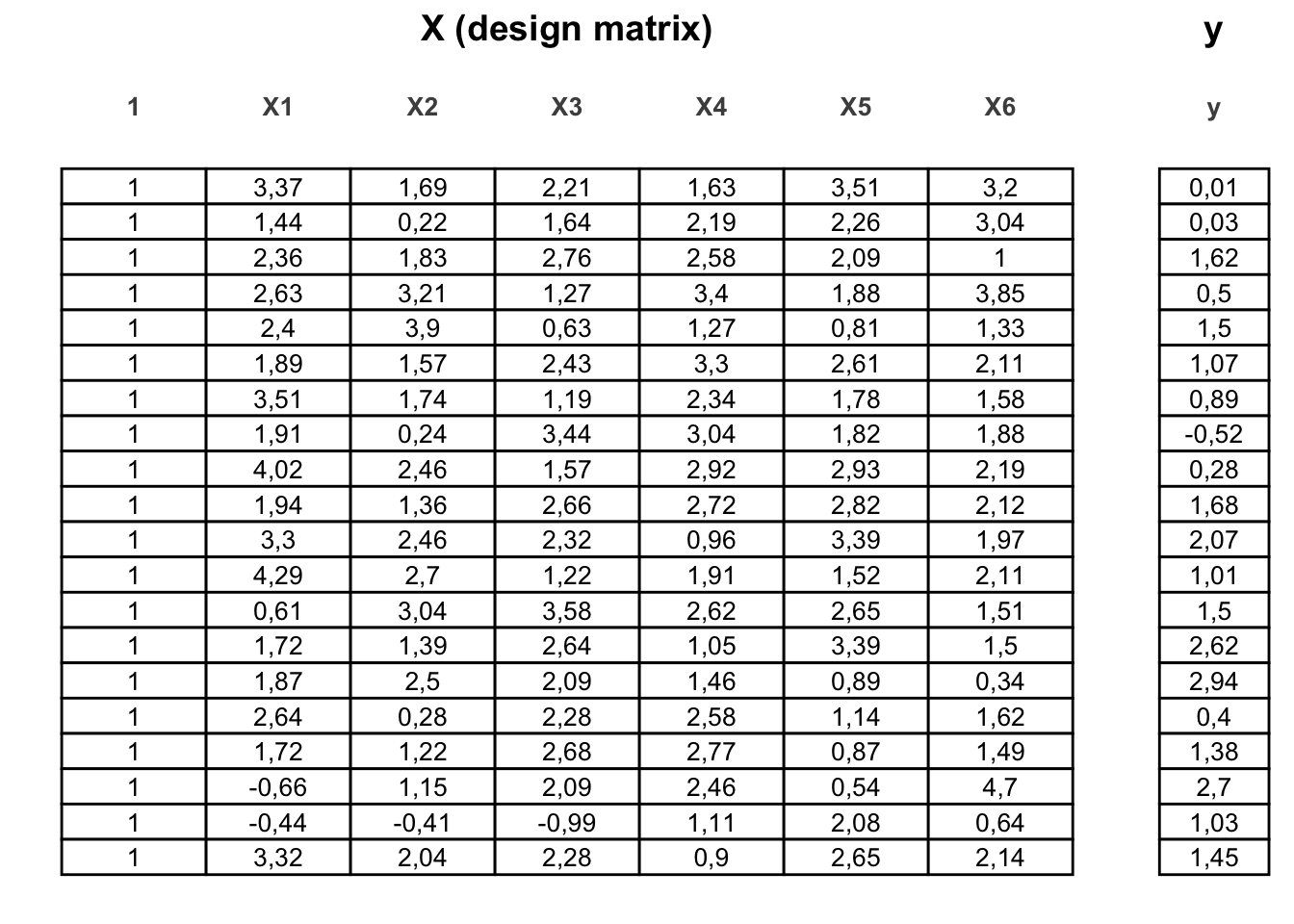
Rysunek 10.2: Macierz układu \(\mathbf{X}\) i wektor odpowiedzi \(\mathbf{y}\) – ilustracja
10.5 Linki
Regresja wieloraka – wizualizacja: https://istats.shinyapps.io/MultivariateRelationship/