Rozdział 5 Standaryzacja i rozkład normalny
5.1 Standaryzacja danych (z-score)
Niekiedy narzędzia statystyki matematycznej, uczenia maszynowego albo analizy danych wymagają standaryzacji danych ilościowych. Standaryzacja zbioru liczb polega na przekształceniu danych za pomocą następującego wzoru:
\[ z = \frac{x - \text{średnia}}{\text{odchylenie standardowe}} \tag{5.1} \]
Powstają w ten sposób wartości standaryzowane, „wyniki z” (po angielsku z scores).
Efektem standaryzacji zmiennych jest sprowadzenie ich do wspólnej skali. Standaryzowane zmienne mają średnią równą 0 i wariancję/odchylenie standardowe wynoszące 1.
5.2 Rozkład normalny
Rozkład normalny to narzędzie matematyczne, które przydaje sie w modelowaniu wielu zbiorów danych ilościowych.
Rozkład wielu zjawisk naturalnych i społecznych jest w przybliżeniu normalny – przykładami mogą być:
- wzrost człowieka,
- waga noworodka lub inne cechy biologiczne,
- odchylenia temperatury od średniej długoterminowej,
- błędy pomiarowe.
W przypadku danych zbliżonych do rozkładu normalnego, histogram układa się w charakterystyczny kształt, przypominający dzwon (stąd określenie „krzywa dzwonowa”, ang. bell curve).
5.3 Reguła empiryczna
W rozkładzie normalnym lub zbliżonym do normalnego4:
około 68% wartości jest oddalonych od średniej co najwyżej o jedno odchylenie standardowe,
około 95% wartości jest oddalonych od średniej co najwyżej o dwa odchylenia standardowe,
około 99,7% wartości (prawie wszystkie) mieści się w zakresie trzech odchyleń standardowych od średniej.
Reguła empiryczna sprawdza się dość dobrze w wielu zbiorach danych, ale nie we wszystkich.
W szczególności w wielu prawdziwych zbiorach danych można z grubsza oszacować odchylenie standardowe na podstawie zasady 95%. Dlatego też odchylenie standardowe jest często interpretowane przez pryzmat reguły empirycznej.
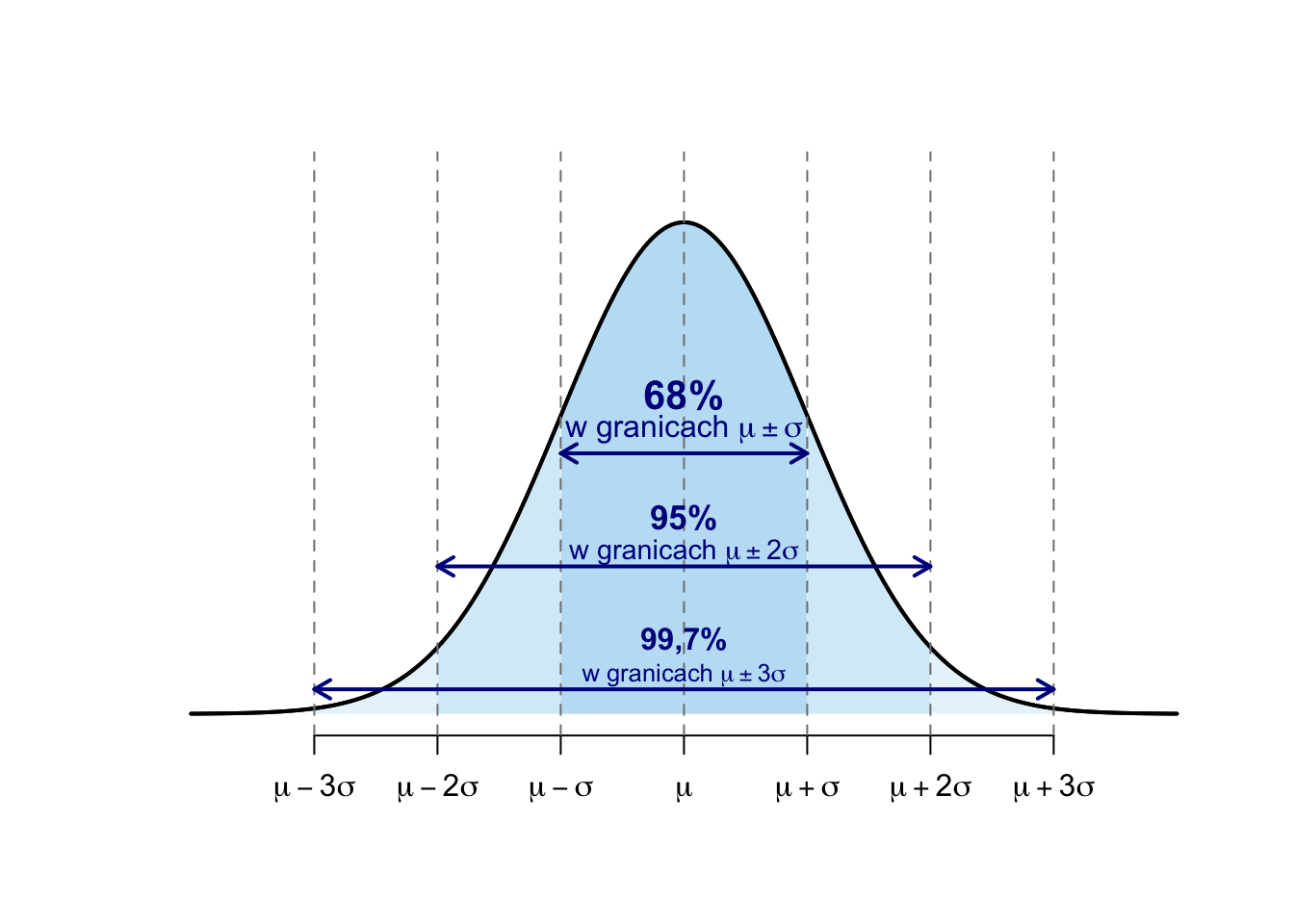
Rysunek 5.1: Reguła empiryczna dla rozkładu normalnego – ilustracja.
5.4 Nierówność Czebyszewa
Reguła empiryczna działa dobrze w przypadku danych w kształcie dzwonu, ale nie wszystkie zbiory danych tak wyglądają. Nierówność Czebyszewa jest bardziej ogólna – ma zastosowanie do każdego zbioru danych, bez względu na jego kształt. Zgodnie z regułą Czebyszewa:
co najmniej 75% wartości mieści się w zakresie dwóch odchyleń standardowych od średniej,
co najmniej 89% w zakresie trzech,
co najmniej 94% w zakresie czterech.
Reguła Czebyszewa podaje wartości ograniczające, a nie najczęstsze. Bywa przydatna, gdy dane są asmetryczne lub nieregularne.
| Odległość od średniej | Reguła empiryczna (rozkład normalny) | Reguła Czebyszewa (dowolny rozkład) |
|---|---|---|
| 1 SD | ~68% | - |
| 2 SD | ~95% | ⩾75% |
| 3 SD | ~99,7% | ⩾89% |
| 4 SD | ~100% | ⩾94% |
5.5 Linki
Reguła empiryczna i krzywa normalna: https://college.cengage.com/nextbook/statistics/utts_13540/student/html/simulation2_4_1.html
Reguła empiryczna w praktyce: https://college.cengage.com/nextbook/statistics/utts_13540/student/html/simulation2_5.html
Piotr Szulc. Czy rozkład normalny jest normalny? https://pl.linkedin.com/posts/piotr-szulc-danetyka_wybory-wyborami-ale-czy-rozkład-normalny-activity-7119939141881987072-BYmd
5.6 Pytania
Pytanie 5.1 Wzrost w pewnej grupie mężczyzn ma w przybliżeniu rozkład normalny ze średnią 179 i odchyleniem standardowym 7.
Adam ma 186 cm wzrostu. Jego z-score to
Bruno ma 172 cm wzrostu. Jego z-score to
Conrad ma 193 cm wzrostu. Jego z-score to
Daniel ma 179 cm wzrostu. Jego z-score to
Emil ma 161.5 cm wzrostu. Jego z-score to
Pytanie 5.2 Wzrost w pewnej grupie mężczyzn ma w przybliżeniu rozkład normalny ze średnią 179 i odchyleniem standardowym 7.
Jakie jest przybliżone prawdopodobieństwo, że losowo wybrany mężczyzna z tej grupy będzie miał między 172 a 186 cm wzrostu?
Jakie jest przybliżone prawdopodobieństwo, że losowo wybrany mężczyzna z tej grupy będzie wyższy niż 193 cm?
.
Jakie jest przybliżone prawdopodobieństwo, że losowo wybrany mężczyzna z tej grupy będzie niższy niż 193 cm?
.
Jakie jest przybliżone prawdopodobieństwo, że losowo wybrany mężczyzna z tej grupy będzie wyższy niż 172 cm?
.
Pytanie 5.3 Histogram przedstawia rozkład dochodów (w tysiącach USD) w określonej populacji.
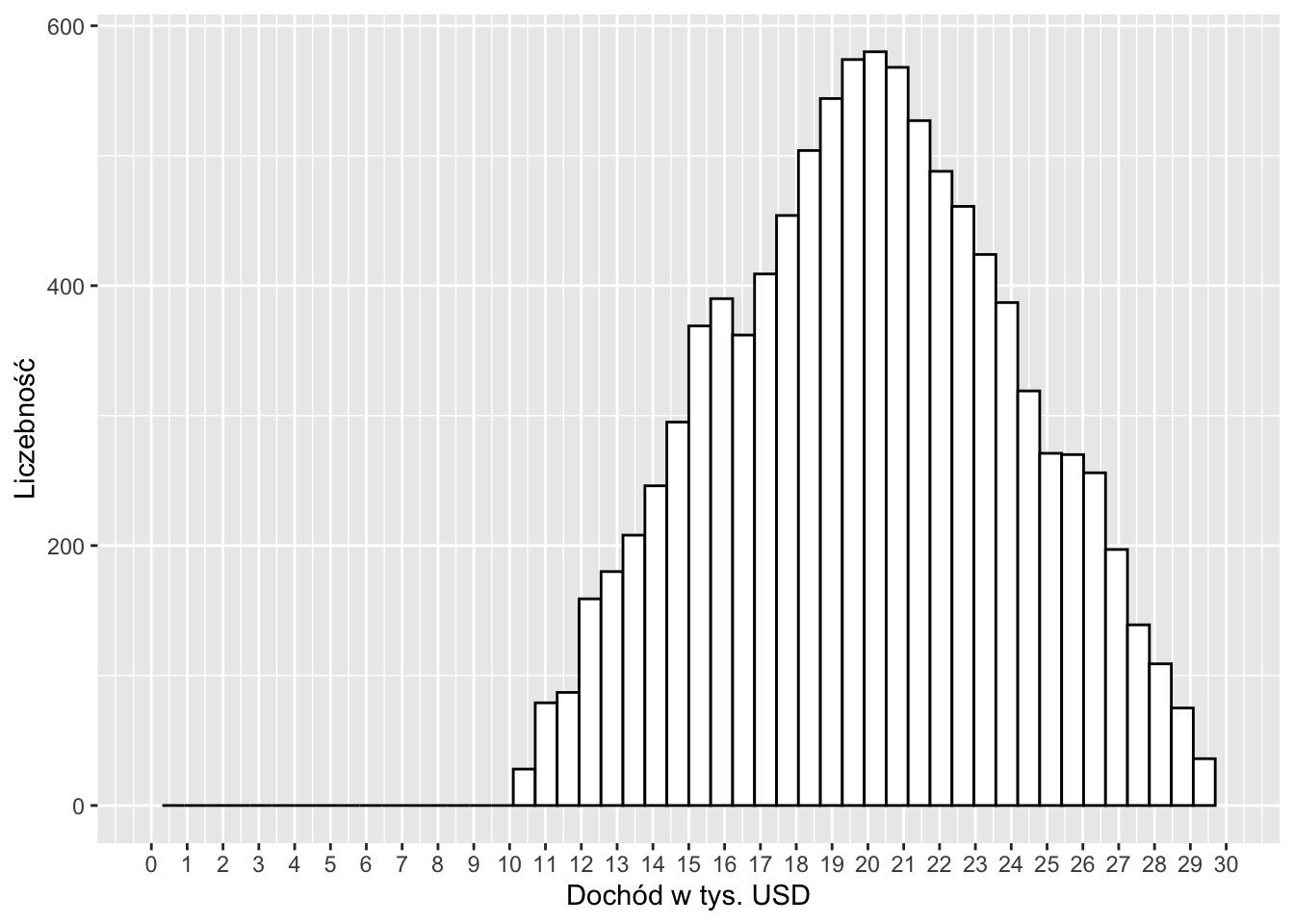
Przeciętny dochód w tej populacji to:
Pierwszy kwartyl w tej populacji to w przybliżeniu:
Odchylenie standardowe w tej populacji to w przybliżeniu:
5.7 Zadania
Zadanie 5.1 Wybierz cechę ilościową w wybranym zbiorze danych i sprawdź, na ile dla tej cechy sprawdza się reguła empiryczna (68%, 95%, 99,7%)
Zadanie 5.2 Znajdź w Internecie siatkę centylową wzrostu chłopców lub dziewcząt i spróbuj oszacować na jej podstawie odchylenie standardowe w rozkładzie wzrostu 10-latków i 18-latków.
Dla rozkładu normalnego te wartości wynoszą, zaokrąglone do dwóch miejsc po przecinku: 68,27%, 95,45% i 99,73%.↩︎